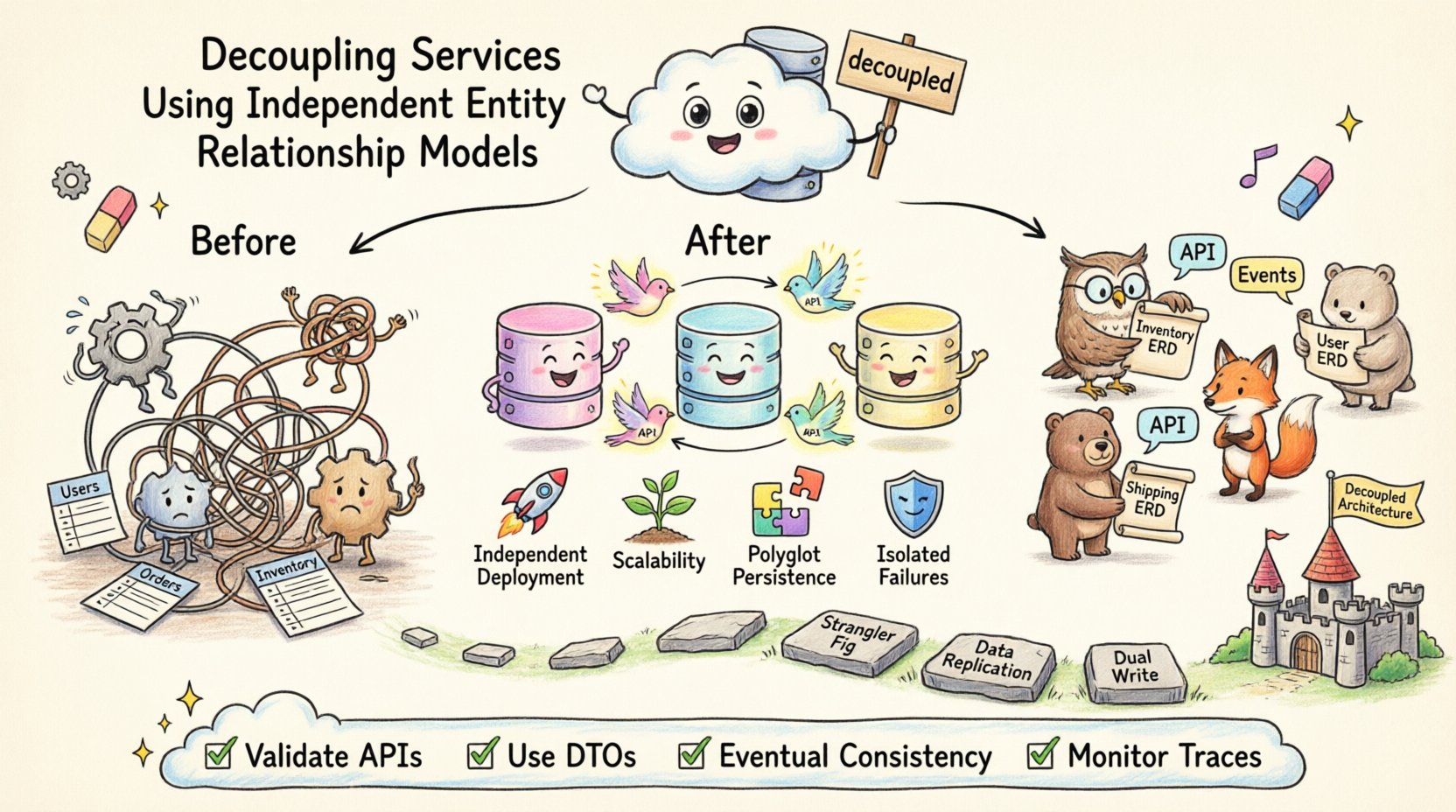
In modern software architecture, the separation of concerns extends beyond code logic into data ownership. When services share a single database schema, they inevitably become dependent on each other’s internal implementations. This tight coupling creates fragility, hinders deployment velocity, and complicates scaling efforts. To achieve true modularity, teams must adopt independent entity relationship models for each service boundary. This approach ensures that data structures remain private to the service that owns them, promoting resilience and autonomy.
🤔 The Challenge of Shared Data
Legacy systems often rely on a monolithic database where multiple application modules query the same tables. While this simplifies initial development, it introduces significant risks as the system grows. A change in one module’s data requirements can break the functionality of another module that relies on that same table structure. This phenomenon is known as the shared database anti-pattern.
Consider a scenario where the User Service needs to add a new field to the profile table. If the Order Service queries that table directly for user names, the update might require a coordinated deployment or a database migration that affects both teams simultaneously. This coordination overhead slows down innovation and increases the risk of production incidents.
Deployment Dependencies: Services cannot be deployed independently if they share schema definitions.
Scalability Limits: A single database often becomes a bottleneck when specific services require more resources than others.
Security Risks: Direct table access bypasses the service layer, potentially exposing sensitive data logic.
🗺️ Defining Independent Entity Relationship Models
An independent entity relationship model (ERD) assigns a specific data schema to a single service. This means the service controls its own database, its own tables, and its own relationships. Other services do not have direct access to these tables. Instead, they interact through defined interfaces, such as APIs or message queues.
This architectural style is often referred to as Database per Service. It aligns data ownership with business capabilities. For example, an Inventory Service manages stock levels, while a Shipping Service manages delivery addresses. Neither service should hold a foreign key reference to the other’s internal tables.
The process involves:
Identifying Boundaries: Determine which data belongs to which business capability.
Designing Local Schemas: Create ERDs that support the specific needs of that service only.
Defining Interfaces: Establish how data is exchanged between services without exposing internal structures.
📈 Key Benefits of Schema Isolation
Adopting independent ERDs transforms how teams manage complexity. It shifts the focus from centralized control to distributed autonomy. Each team can optimize their data storage strategy without worrying about global impacts.
Aspect | Shared Database Model | Independent ERD Model |
|---|---|---|
Deployment | Coordinated, risky | Independent, frequent |
Scalability | Horizontal only (cluster) | Vertical per service |
Technology | Single DB type | Polyglot persistence |
Failure Domain | Single point of failure | Isolated failures |
🔗 Designing for Loose Coupling
When services cannot talk directly to each other’s databases, they must communicate through APIs. This requires careful design of the contract between services. The API becomes the only shared contract. If the API contract remains stable, the underlying data model can change without affecting consumers.
API Versioning: Since data models evolve, APIs must support versioning. This allows old clients to function while new clients adopt updated structures.
Data Transfer Objects (DTOs): Do not expose entity objects directly. Create specific DTOs that carry only the data necessary for the consumer. This prevents internal changes from leaking outward.
Validation: Validate input at the API boundary, not at the database level alone.
Idempotency: Ensure operations can be repeated safely without causing duplicate records.
Documentation: Maintain clear documentation for all data exchange formats.
⚖️ Handling Transactions and Consistency
One of the most significant challenges in decoupling is maintaining data integrity. In a shared database, a transaction can span multiple tables easily. In a distributed system, a single logical transaction may span multiple services. This is known as the Distributed Transaction Problem.
To solve this, teams often adopt the Eventual Consistency pattern. Instead of ensuring data is identical everywhere immediately, the system ensures it becomes consistent over time. This is achieved through asynchronous messaging.
Saga Pattern: A saga is a sequence of local transactions. Each transaction updates the database and publishes an event to trigger the next transaction. If a step fails, compensating transactions are executed to undo previous changes.
Outbox Pattern: Write events to a local table alongside the main data change. A background process publishes these events, ensuring no data is lost.
Idempotent Consumers: Message handlers must handle duplicate messages gracefully.
Compensating Actions: Define clear rollback logic for every forward action.
🚚 Migration Strategies
Moving from a shared database to independent ERDs is a significant undertaking. It requires a phased approach to minimize risk. Rushing the migration can lead to data loss or service outages.
Strangler Fig Pattern: Gradually move functionality to new services. Start with a specific feature, such as user notifications. Build a new service with its own ERD for that feature. Route traffic to the new service while keeping the legacy system running.
Data Replication: During the transition, you may need to keep data in sync between the old and new databases. This allows the new service to read data from the old system temporarily while it populates its own.
Dual Write: Write to both the old and new databases simultaneously during the migration window. Verify the new service works correctly before disabling the old writes.
🔍 Monitoring and Maintenance
With independent data stores, monitoring becomes more complex. You are no longer looking at a single database health dashboard. You must aggregate logs and metrics from multiple sources.
Distributed Tracing: Implement tracing to follow a request as it passes through different services. This helps identify which service is causing latency or errors.
Schema Registry: Maintain a registry of API contracts. This ensures that any change to a data model is reviewed and approved before deployment.
Alerting: Set alerts for replication lag and message queue backlogs.
Capacity Planning: Monitor storage growth per service to prevent unexpected costs.
Backup Strategies: Ensure each service has its own backup and recovery plan.
🛠️ Common Pitfalls to Avoid
Even with a solid plan, teams often stumble during implementation. Understanding these common mistakes can save significant time and effort.
Hidden Coupling: Avoid using database views or shared tables even if they are in separate schemas. Direct database access should be forbidden.
Over-fragmentation: Do not create a new database for every tiny function. Group related entities into logical services.
Ignoring Latency: Network calls are slower than local queries. Design APIs to minimize round trips.
Complex Queries: Avoid cross-service joins. If you need data from multiple services, query them separately and merge the results in the application layer.
🧱 Final Thoughts
Decoupling services using independent entity relationship models is a strategic decision that pays off in the long run. It requires discipline in design and a willingness to manage distributed complexity. However, the result is a system that is easier to scale, more resilient to failure, and faster to evolve. By owning their data, services gain the autonomy needed to innovate without constant coordination.
Start by identifying the most critical boundaries in your system. Isolate the data for those services first. Refine your API contracts and messaging patterns as you go. This incremental approach ensures stability while moving toward a fully decoupled architecture.