Designing a robust data architecture requires more than just connecting tables; it demands a rigorous approach to structure and integrity. For data architects, normalization is not merely a theoretical exercise found in textbooks—it is the backbone of maintainable, scalable, and reliable database systems. When constructing Entity Relationship Diagrams (ERD), the decisions made during the schema design phase dictate the long-term health of the application. Proper normalization minimizes data redundancy and ensures logical consistency, preventing cascading errors down the line.
This guide outlines the essential normalization rules that every data architect must apply. We will explore the progression from basic atomicity to complex dependencies, examining how each rule impacts storage, query performance, and data quality. By adhering to these principles, you build systems that stand the test of time.
Why Structure Matters in Schema Design 📐
Before diving into specific forms, it is crucial to understand the objective behind normalization. The primary goal is to isolate data so that modifications, deletions, and insertions do not cause anomalies. Without a structured approach, databases become prone to three specific types of anomalies:
Insertion Anomalies: Inability to add data about one entity without adding data about another unrelated entity.
Update Anomalies: The need to update the same value in multiple rows, risking inconsistency if one row is missed.
Deletion Anomalies: Losing data about one entity when deleting data about another.
Normalization addresses these issues by organizing attributes into tables based on dependency rules. This separation allows the database to function as a single source of truth. While the process can seem tedious, the reduction in maintenance overhead and data corruption risks makes it a critical investment.
The Foundation: First Normal Form (1NF) 🧱
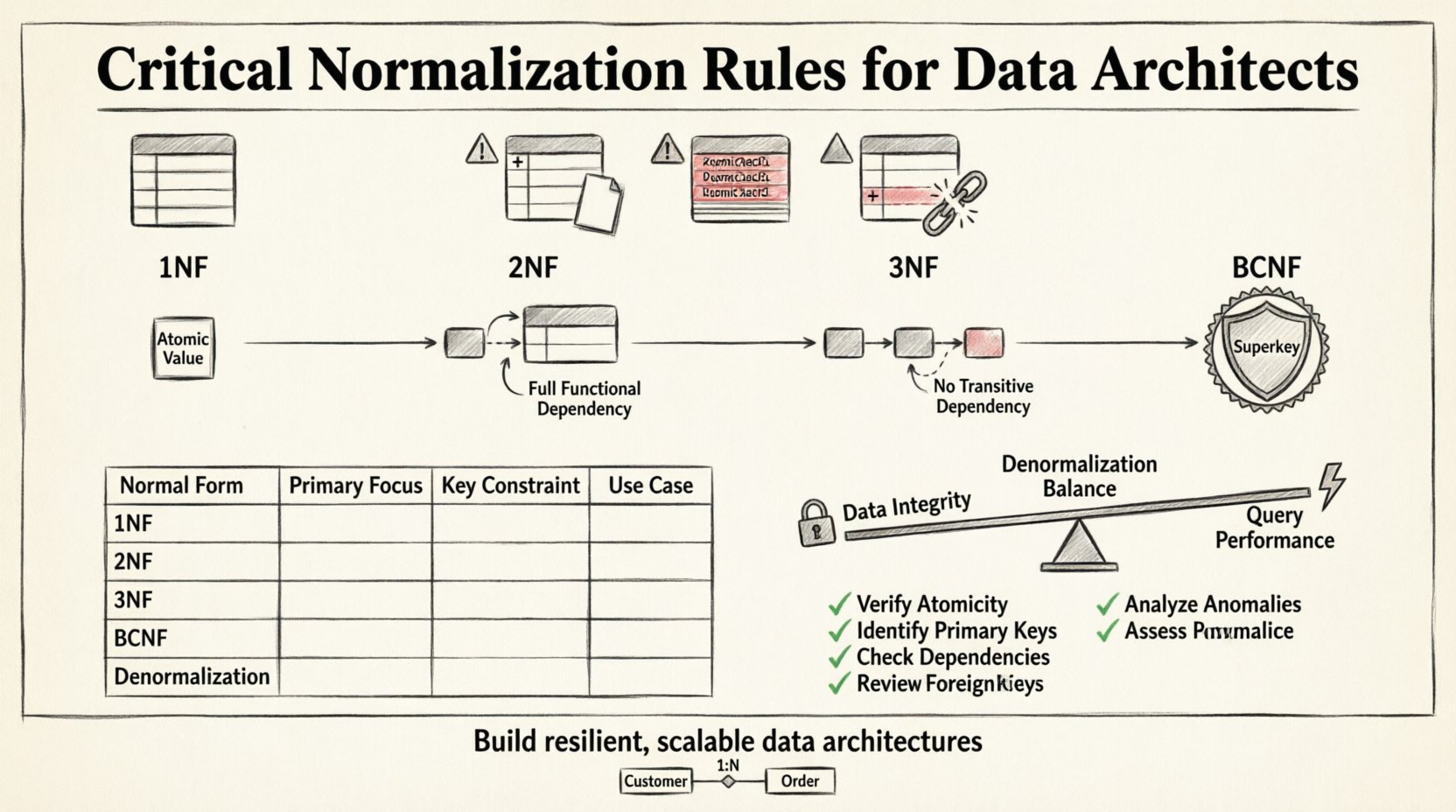
The first step in normalization is achieving the First Normal Form. This is the baseline requirement for any relational database. A table is in 1NF if it satisfies two conditions: it contains only atomic values, and each column contains only one value per row. There should be no repeating groups or arrays within a single cell.
Violations of 1NF often occur when developers attempt to store lists in a single column, such as storing multiple phone numbers in one field separated by commas. This approach complicates querying and indexing. Instead, each piece of data should exist in its own row.
Atomicity: Ensure every column holds a single, indivisible value.
Unique Rows: Every row must be unique, often enforced by a primary key.
Column Order: The order of columns should not affect the meaning of the data.
Consider a customer table. If a customer has three email addresses, do not create three email columns. Create a separate “Email” table linked by a foreign key. This structure ensures that adding a fourth email does not require altering the table schema.
Eliminating Partial Dependencies (2NF) ⚖️
Once a table is in 1NF, the next step is to check for partial dependencies. A table is in Second Normal Form if it is already in 1NF and every non-key attribute is fully dependent on the primary key. This rule becomes particularly relevant when dealing with composite primary keys.
A composite primary key consists of two or more columns. In this scenario, a partial dependency occurs if a non-key attribute depends on only part of the composite key. For example, in a table tracking order items where the primary key is (OrderID, ProductID), a column for “ProductName” might depend only on “ProductID”, not the combination of both.
Full Dependency: Ensure every non-key field relies on the entire primary key.
Separation of Concerns: Move attributes that depend on a subset of the key into a new table.
Integrity Checks: Verify that no attribute can be inferred without the full key.
By moving “ProductName” to its own table linked by “ProductID”, you eliminate the risk of the name changing in one order but not another. This reduces the storage required and ensures consistency across all order records.
Removing Transitive Dependencies (3NF) 🔗
Third Normal Form takes the structure a step further by addressing transitive dependencies. A table is in 3NF if it is in 2NF and all non-key attributes are non-transitively dependent on the primary key. Essentially, this means that non-key columns should not depend on other non-key columns.
Imagine a table with EmployeeID, EmployeeName, DepartmentID, and DepartmentName. If EmployeeName determines DepartmentName, you have a transitive dependency. If an employee changes departments, the DepartmentName in the employee table might become outdated if not updated correctly. To fix this, the Department table should be separated.
Direct Dependencies Only: Attributes should depend directly on the key, not on other attributes.
Logical Grouping: Group related attributes that share a common determinant into their own entities.
Foreign Keys: Use foreign keys to link the separated tables together.
This separation ensures that department information is stored once. If the department name changes, it is updated in one place, and all employee records reflect the change automatically through the relationship.
When 3NF Isn’t Enough: BCNF & Beyond 🚀
While 3NF covers most standard design scenarios, there are edge cases where strict 3NF is insufficient. Boyce-Codd Normal Form (BCNF) is a stricter version of 3NF that handles cases where there are multiple candidate keys. BCNF requires that for every functional dependency X → Y, X must be a superkey.
Consider a scenario where a student can have multiple teachers, and a teacher can teach multiple subjects. If the primary key is (Student, Subject), and a teacher is assigned based on the subject, you might encounter situations where the dependency logic overlaps in complex ways. BCNF ensures that no column is determined by a set of columns that is not a candidate key.
Superkey Requirement: The determinant in any dependency must be a superkey.
Complex Relationships: Handle many-to-many relationships with intermediate tables.
Overhead Consideration: Higher normal forms can increase join complexity.
Fourth Normal Form (4NF) and Fifth Normal Form (5NF) deal with multi-valued dependencies and join dependencies. These are rare in general business applications but are critical in specialized data warehousing or scientific data modeling.
The Art of Strategic Denormalization ⚡
Normalization is not always the end goal. In some high-performance environments, strict normalization can lead to excessive joins that degrade query speed. This is where strategic denormalization comes into play. Denormalization involves adding redundant data to a database to optimize read performance.
However, this should never be done arbitrarily. It requires a clear understanding of the trade-offs between read speed and write complexity. When read operations significantly outweigh write operations, redundancy might be justified.
Read-Heavy Workloads: If reporting is the primary function, denormalization can reduce query time.
Caching Layers: Use application-level caching before altering the schema.
Data Consistency Risks: Be aware that redundant data can drift out of sync.
Write Penalties: Every write operation must update all redundant copies of the data.
A common pattern is to denormalize summary tables for reporting dashboards while keeping the core transactional data in 3NF. This hybrid approach balances integrity with performance.
Comparison of Normal Forms
Normal Form | Primary Focus | Key Constraint | Typical Use Case |
|---|---|---|---|
1NF | Atomic Values | No repeating groups | Initial Schema Design |
2NF | Full Dependency | No partial dependencies on composite keys | Complex Keys |
3NF | Transitive Dependency | Non-key attributes depend only on the key | General Business Logic |
BCNF | Superkeys | Determinant must be a superkey | Complex Candidate Keys |
A Practical Checklist for Data Architects ✅
To ensure your ERD meets industry standards, run through this checklist during the design phase. This process helps identify potential issues before code is written.
Verify Atomicity: Ensure no column contains multiple distinct values.
Identify Primary Keys: Confirm every table has a unique identifier.
Check Dependencies: Map out how each column relates to the primary key.
Review Foreign Keys: Ensure relationships are explicitly defined.
Analyze Anomalies: Simulate insert, update, and delete operations mentally.
Assess Performance: Determine if 3NF is sufficient or if denormalization is needed.
Document Constraints: Clearly define rules for data entry and validation.
Plan for Growth: Consider how the schema will handle increased data volume.
By following these steps, you create a schema that is resilient to change. Data architecture is not static; it evolves with business needs. A well-normalized foundation makes this evolution smoother, as changes to one part of the system do not ripple unpredictably through the rest.
Remember that normalization is a tool, not a law. While 3NF is the standard for transactional systems, the specific needs of your application might dictate deviations. The goal is always data integrity and system efficiency. Balance these two factors carefully, and your ERD will serve as a solid foundation for the entire application ecosystem.
Adopting these critical normalization rules empowers you to build systems that are not only functional today but adaptable for the future. Focus on the relationships between data points, and the structure will follow naturally.