Entity Relationship Diagrams (ERDs) serve as the blueprint for database architecture. They define how data is structured, stored, and retrieved within a system. When these diagrams are flawed, the consequences extend far beyond the development phase. Errors in production environments can lead to data corruption, performance bottlenecks, and significant financial loss. Understanding the common pitfalls is essential for maintaining system integrity.
Many teams rush through the modeling phase, prioritizing speed over precision. This haste often results in schema issues that are difficult to resolve once data begins flowing. A robust design requires careful consideration of relationships, data types, and constraints. Below, we explore the most frequent design flaws and their technical implications.
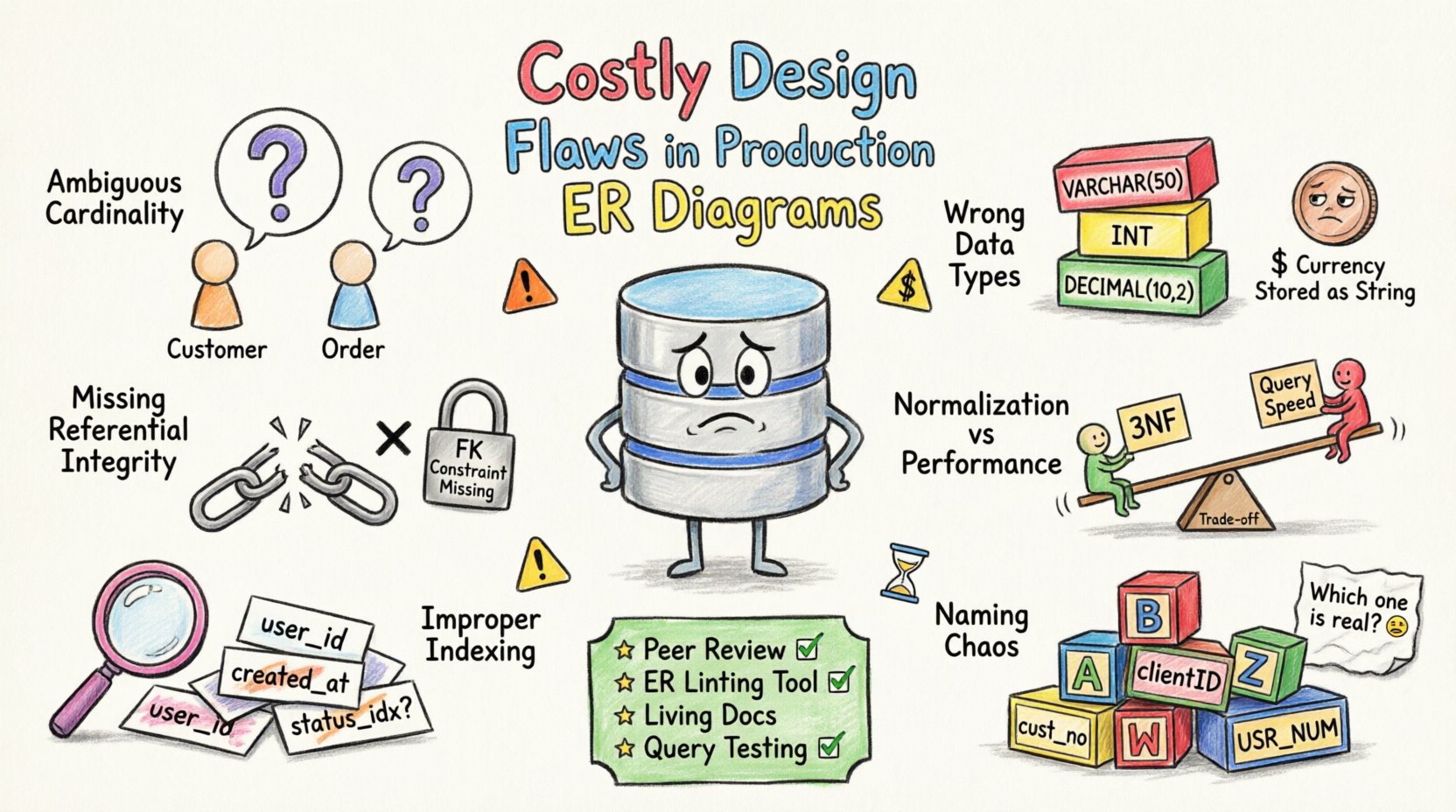
1. Ambiguous Cardinality and Relationships 🔗
Cardinality defines the numerical relationship between entities. Incorrect cardinality leads to logical errors in data retrieval and storage. A common mistake is assuming a one-to-one relationship when a one-to-many scenario exists.
- Many-to-Many Omission: Failing to create a junction table for many-to-many relationships forces data duplication or complex join queries.
- Undefined Foreign Keys: Without explicit foreign keys, the database cannot enforce referential integrity, allowing orphaned records.
- Optional vs. Mandatory: Misclassifying a required relationship as optional introduces null values where data is expected.
For example, consider a customer and an order. If the diagram implies a customer can exist without an order but the application logic requires it, the database will store incomplete profiles. This discrepancy causes application crashes or inconsistent reporting.
2. Inconsistent Data Type Selection 📊
Data types determine how information is stored and processed. Selecting the wrong type consumes unnecessary storage or limits the range of values. Precision issues often arise when floating-point numbers are used for currency.
- Integer Overflow: Using small integers for identifiers can lead to overflow errors as the dataset grows.
- Text Length: Using fixed-length character fields wastes space for variable-length data.
- Date Precision: Storing dates without time zones creates synchronization issues across distributed systems.
Choosing a generic text field for phone numbers is another frequent error. This allows invalid characters to enter the system, complicating validation logic later. Numeric fields should be used for calculations, and text fields only for alphanumeric data.
3. Missing Referential Integrity Constraints 🔒
Referential integrity ensures that relationships between tables remain consistent. Without these constraints, the database relies on application code to maintain data accuracy, which is prone to human error.
- No Cascade Rules: Deleting a parent record without cascade rules leaves child records dangling in the database.
- Missing Constraints: Relying on application-level validation instead of database constraints is insufficient.
- Soft Deletes: Improper handling of deleted records creates clutter and slows down query performance.
When constraints are missing, data integrity relies entirely on the application developers. If a bug allows a direct write to the database, inconsistencies become permanent. This is a primary cause of data corruption in long-running production systems.
4. Normalization vs. Performance Trade-offs ⚖️
Normalization reduces redundancy but can increase query complexity. Over-normalization leads to excessive joins, while under-normalization creates update anomalies. Finding the balance is critical for performance.
- Third Normal Form (3NF): Often ideal for transactional systems but may require denormalization for read-heavy workloads.
- Denormalization: Introducing redundancy for performance must be documented to prevent update conflicts.
- Query Complexity: Deeply normalized schemas require complex joins that strain the database engine.
Teams often normalize to the extreme to ensure data purity, ignoring the cost of joining multiple tables. In high-traffic environments, this results in slow response times. Strategic denormalization can improve read performance, provided write operations are managed correctly.
5. Improper Indexing Strategy 🏷️
Indexes speed up data retrieval but slow down write operations. A flawed ERD often fails to account for how data will be queried. This leads to full table scans and high latency.
- Missing Foreign Key Indexes: Joins on non-indexed columns are computationally expensive.
- Over-Indexing: Too many indexes increase write latency and storage requirements.
- Composite Index Order: Incorrect column ordering in composite indexes renders them ineffective.
An index on a frequently queried column is standard practice. However, ignoring the query patterns during the design phase leads to inefficient access paths. Regular review of query execution plans is necessary to adjust indexing strategies.
6. Naming Convention Chaos 🏷️
Consistent naming conventions are vital for maintainability. Inconsistent table and column names make the schema difficult to understand and modify.
- Mixed Case: Using camelCase in some places and snake_case in others creates confusion.
- Ambiguous Abbreviations: Short names like “cust” or “ord” lack clarity for new team members.
- Reserved Keywords: Using reserved words as table names causes syntax errors in queries.
Clear naming reduces the cognitive load on developers and database administrators. It also facilitates automated documentation generation and reduces the likelihood of typos in SQL statements.
Impact Analysis of Common Flaws
| Design Flaw | Technical Impact | Business Cost |
|---|---|---|
| Missing Foreign Keys | Orphaned records, data inconsistency | Data loss, compliance violations |
| Incorrect Data Types | Storage waste, calculation errors | Financial discrepancies, reporting errors |
| Over-Normalization | Slow query performance, high latency | Slow user experience, lost revenue |
| Missing Indexes | Full table scans, database lock contention | System downtime, poor scalability |
| Poor Naming | High maintenance overhead, error rates | Increased development time, bugs |
Prevention Strategies 🛡️
Preventing these flaws requires a disciplined approach to database design. The following steps help mitigate risks before deployment.
- Peer Reviews: Implement mandatory schema reviews before any changes are merged.
- Automated Linting: Use tools to check for naming conventions and structural standards.
- Documentation: Maintain up-to-date ERD diagrams that reflect the actual schema.
- Testing: Run schema validation tests in the staging environment before production.
Adopting a version control process for database schemas ensures that changes are tracked and reversible. This allows teams to identify when a flaw was introduced and roll back if necessary. Collaboration between developers and architects is essential to catch issues early.
Long-Term Maintenance Considerations 🔄
Database schemas evolve over time. A design that works today may not suit future requirements. Regular audits help identify technical debt and outdated patterns.
- Schema Drift: Monitor differences between the ERD and the live database.
- Deprecation: Plan for the removal of unused tables and columns.
- Scalability: Design with partitioning and sharding in mind for large datasets.
Ignoring maintenance leads to a fragile system that resists change. Proactive management ensures the database remains a reliable foundation for the application. Investing time in the initial design pays dividends throughout the lifecycle of the software.
Final Thoughts on Schema Integrity 📝
Production database errors are often the result of overlooked details in the design phase. By addressing cardinality, data types, constraints, and indexing, teams can build more resilient systems. The cost of fixing a flaw in production is significantly higher than preventing it during modeling.
Focus on clarity, consistency, and validation. A well-structured ERD is the backbone of data reliability. Prioritize quality over speed to ensure long-term stability. This approach minimizes risk and maximizes the value of the data stored within the system.