Designing a robust database structure is a balancing act. On one side, you have data integrity and the elimination of redundancy through normalization. On the other, you have query speed and system responsiveness. Many database architects face a difficult choice: stick to strict normalization rules and risk slow queries, or denormalize aggressively and risk data inconsistencies. The goal is to find a middle ground where the database adheres to Third Normal Form (3NF) while maintaining high performance. This article explores how to structure Entity Relationship Diagrams (ERD) to achieve this equilibrium without compromising either integrity or speed.
Understanding Third Normal Form 🧩
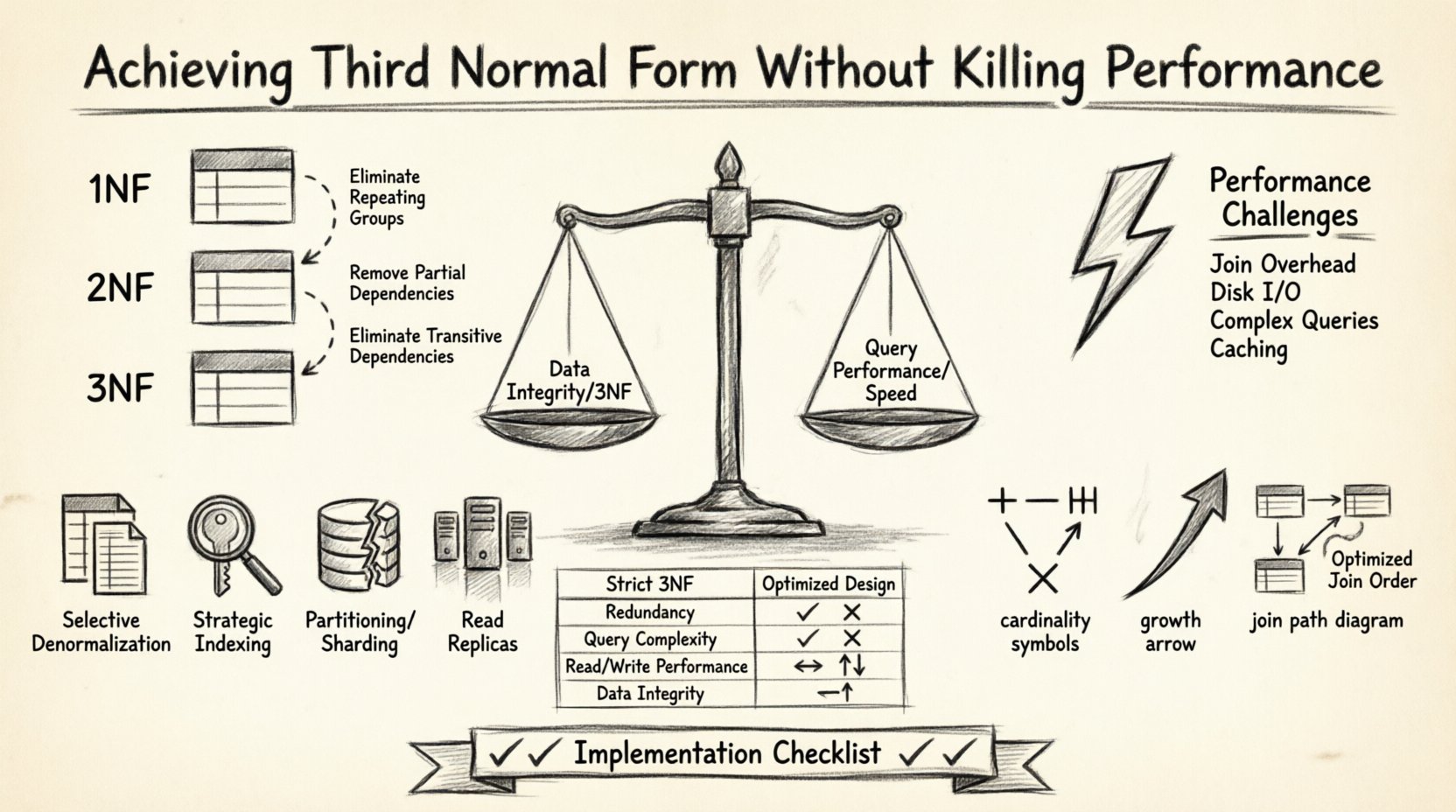
Third Normal Form is a specific level of database normalization. Before reaching 3NF, a table must first satisfy First Normal Form (1NF) and Second Normal Form (2NF). The core principle of 3NF is that all attributes must depend only on the primary key. There should be no transitive dependencies.
- First Normal Form: Eliminates repeating groups and ensures atomic values.
- Second Normal Form: Removes partial dependencies where non-key attributes depend on only part of a composite key.
- Third Normal Form: Removes transitive dependencies. If A determines B, and B determines C, then C should not depend directly on A in the same table.
When you reach 3NF, you minimize update anomalies. These are errors that occur when data is changed in one place but not others, leading to inconsistencies. For example, if a customer’s address is stored in both the Orders table and the Customers table, changing the address in one table but not the other creates a discrepancy. 3NF forces you to store that address in one place only.
The Performance Trade-Off ⚡
While 3NF is excellent for data integrity, it often comes at a cost to performance. Normalized databases typically require more tables. To retrieve a complete dataset, the database engine must perform multiple joins. Each join operation requires the system to read data from disk or memory, match keys, and combine results.
Consider a reporting query that needs customer names, order details, product descriptions, and shipping addresses. In a fully normalized 3NF design, this might involve joining five or more tables. If the data volume is large, these joins can become a bottleneck.
Here are the specific performance challenges associated with 3NF:
- Increased Join Overhead: Every relationship requires a join operation during read queries.
- Disk I/O: Spreading data across many tables increases the number of pages the database engine must access.
- Complex Query Logic: Applications must construct more complex SQL statements to fetch related data.
- Caching Complexity: Caching a single denormalized row is simpler than caching multiple related rows.
Strategies for Balancing Integrity and Speed 🚀
You do not need to abandon normalization to improve performance. There are specific techniques to optimize a 3NF database while keeping the structure intact. The following strategies help maintain data quality without sacrificing speed.
1. Selective Denormalization
Not every table needs to be strictly 3NF. Identify the read-heavy tables and the critical data paths. You can introduce controlled redundancy in these specific areas. For instance, store a customer’s name directly in the Orders table. While this duplicates data, the performance gain for order lookups is significant. You must then implement a trigger or application logic to keep this copy updated when the customer record changes.
2. Strategic Indexing
Indexes are the primary tool for speeding up joins. Without indexes, a database performs a full table scan for every join condition. With proper indexing, lookups become nearly instantaneous.
- Foreign Key Indexes: Always index columns used in foreign key relationships. This ensures that joining tables is fast.
- Composite Indexes: Create indexes on multiple columns if your queries frequently filter by that combination.
- Covering Indexes: Design indexes that include all columns needed for a specific query. This allows the database to satisfy the query using only the index, avoiding a lookup to the main table data.
3. Partitioning and Sharding
If the dataset grows too large, splitting the tables can improve performance. Partitioning divides a large table into smaller, more manageable physical pieces based on a key, such as date or region. Sharding distributes data across multiple database instances. Both methods reduce the amount of data the engine needs to scan to answer a specific query.
4. Read Replicas
Separate your write operations from your read operations. Use a primary database instance for transactions and updates. Replicate that data to one or more read-only replicas. Complex reporting queries that strain the system can run on the replicas, keeping the main system fast for user interactions.
ERD Design Considerations 📐
When drawing an Entity Relationship Diagram, the visual representation influences how developers write queries. A clear ERD helps identify relationships early. However, a diagram that looks perfect on paper might perform poorly in production. Here is how to approach ERD design for performance.
- Identify Cardinality Clearly: Ensure every relationship has a defined cardinality (one-to-one, one-to-many, many-to-many). Ambiguous relationships lead to inefficient joins.
- Plan for Growth: Anticipate future data volume. A design that works for 10,000 rows might fail with 10 million rows.
- Review Join Paths: Trace the paths a common query will take through the diagram. If a path is too long, consider adding a denormalized column.
- Document Constraints: Explicitly document which constraints are enforced by the database and which are handled by the application layer.
Comparison: Normalized vs. Optimized Design 📊
The table below illustrates the differences between a strict 3NF approach and an optimized approach for a specific scenario.
| Feature | Strict 3NF Design | Optimized Design |
|---|---|---|
| Redundancy | Minimal | Controlled and limited |
| Query Complexity | High (Multiple Joins) | Moderate (Fewer Joins) |
| Write Performance | Fast (Less Data) | Variable (Update Triggers) |
| Read Performance | Slower (Disk I/O) | Faster (Cached Data) |
| Data Integrity | High | High (with Validation) |
When to Break the Rules 🛑
There are valid scenarios where strict 3NF should be set aside. Understanding when to deviate is crucial for database architects.
- Reporting and Analytics: Data warehouses often use a star schema rather than 3NF. The goal here is read speed for analysis, not transactional integrity.
- High-Throughput Transactional Systems: If the system handles millions of writes per second, complex joins might cause lock contention. Simplifying the schema can reduce locking overhead.
- Legacy Systems: If migrating from an old system, it might be faster to denormalize temporarily while rebuilding the application layer.
- Read-Heavy Applications: If your application reads data 100 times for every write, the cost of maintaining 3NF consistency outweighs the benefits.
Implementation Checklist ✅
Before deploying your database schema, run through this checklist to ensure you have balanced performance and normalization.
- Analyze Query Patterns: Identify the most frequent read queries. Do they require too many joins?
- Measure Current Performance: Baseline your system. Know the current latency of critical queries.
- Review Index Usage: Check if indexes are being utilized or if they are causing overhead during writes.
- Test Write Load: Ensure that any denormalization strategy does not slow down write operations too much.
- Plan for Data Sync: If you duplicate data, how will you keep it in sync? Define the mechanism.
- Monitor Anomalies: Set up alerts for data inconsistencies if you are using partial denormalization.
Final Thoughts on Database Architecture 🏗️
Achieving Third Normal Form without killing performance requires a nuanced approach. It is not a binary choice between speed and integrity. By understanding the cost of joins, utilizing indexes effectively, and applying selective denormalization where appropriate, you can build systems that are both reliable and fast. The best database design is one that aligns with the specific workload of the application. Regularly review your ERD and query performance as the system grows. Adaptation is key to long-term success in data management.