











Các cơ sở dữ liệu quan hệ được xây dựng trên nền tảng của các bảng và hàng, một cấu trúc được thiết kế cho dữ liệu phẳng. Tuy nhiên, thế giới thực hiếm khi tuân theo sự đơn giản như vậy. Các tổ chức, hệ thống tập tin, các chuỗi bình luận và cây danh mục đều tồn tại trongcác cấu trúc phân cấp. Việc biểu diễn các mối quan hệ cha-con này trong một sơ đồ Thực thể – Mối quan hệ (ERD) chuẩn yêu cầu các mẫu thiết kế cụ thể nhằm duy trì tính toàn vẹn dữ liệu đồng thời cho phép truy xuất hiệu quả.
Khi bạn cố gắng ánh xạ một cấu trúc cây vào một lược đồ phẳng, bạn sẽ gặp phải mâu thuẫn kinh điển giữa chuẩn hóa và hiệu suất. Hướng dẫn này khám phá các kỹ thuật cốt lõi để mô hình hóa dữ liệu phân cấp, đánh giá các điểm trao đổi của từng phương pháp để giúp bạn thiết kế các hệ thống vững chắc.
🧩 Thách thức của Các Lược đồ Phẳng
Một sơ đồ Thực thể – Mối quan hệ thường biểu diễn các thực thể dưới dạng hình hộp và các mối quan hệ dưới dạng đường thẳng. Trong một mối quan hệ chuẩn, một bảng liên kết với bảng khác thông qua Khóa ngoại. Điều này hoạt động hoàn hảo cho các tình huống nhiều-nhiều hoặc một-nhiều, nơi hướng liên kết là cố định. Nhưng điều gì xảy ra khi một danh mục có thể có các danh mục con, những danh mục con này lại có thể có các danh mục con con, có thể kéo dài vô hạn?
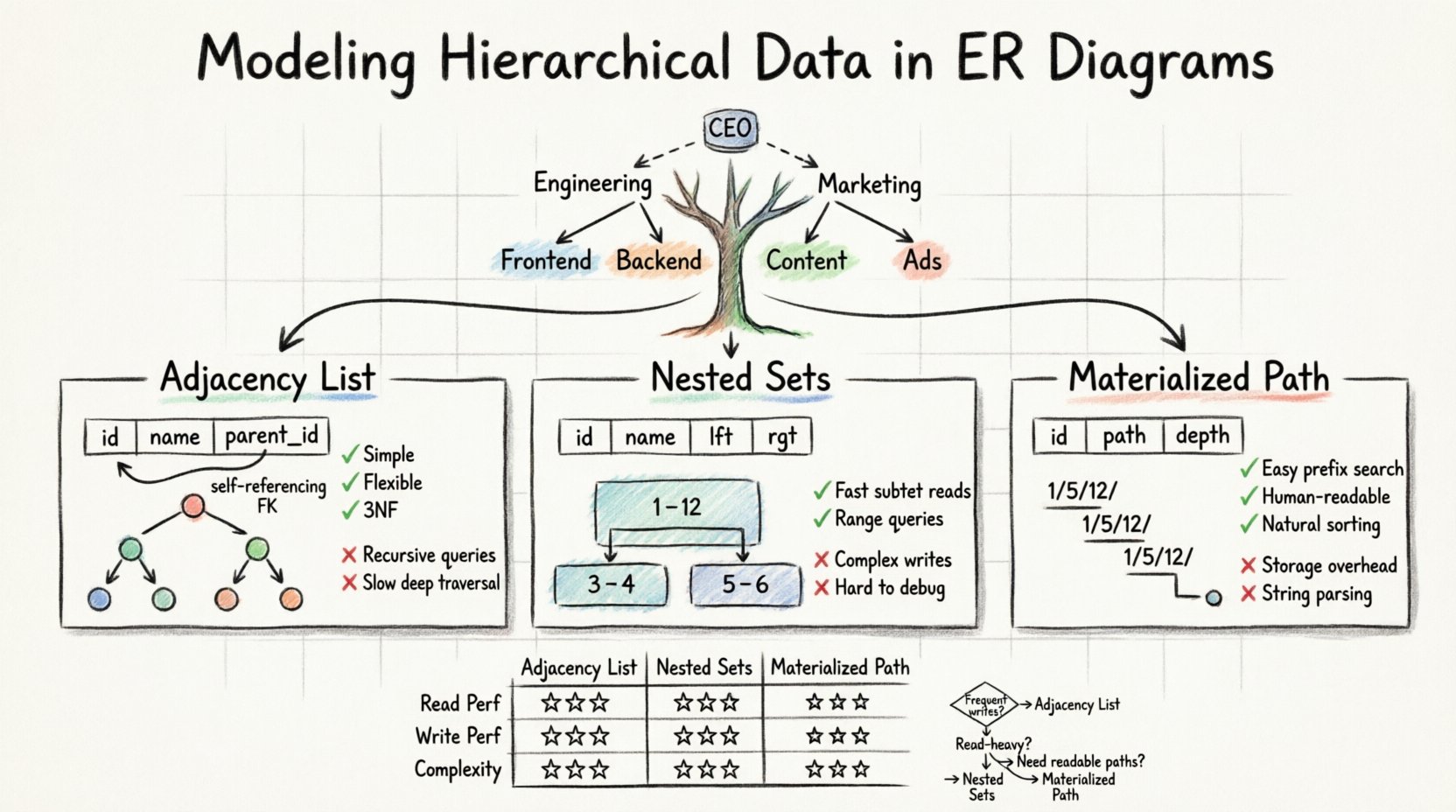
Các mô hình quan hệ chuẩn gặp khó khăn với độ sâu thay đổi. Một bảng phẳng không thể dễ dàng lưu trữ một đường đi có độ dài tùy ý. Để giải quyết vấn đề này, chúng ta phải điều chỉnh lược đồ để lưu trữ phân cấp một cách rõ ràng. Có ba mẫu chính được các kiến trúc sư dữ liệu sử dụng để đạt được điều này:
- Danh sách Kề: Lưu trữ ID cha bên trong bản ghi con.
- Các Tập hợp Lồng ghép: Gán các giá trị trái và phải để xác định các khoảng.
- Đánh số Đường đi: Lưu trữ toàn bộ đường đi từ nút gốc đến nút hiện tại.
🔗 Mô hình Danh sách Kề
Danh sách Kề là phương pháp phổ biến và đơn giản nhất để biểu diễn phân cấp trong một sơ đồ ERD chuẩn. Nó dựa vào mối quan hệ tự tham chiếu. Điều này có nghĩa là một bảng duy nhất chứa một cột tham chiếu đến khóa chính của chính nó.
📐 Cấu trúc Lược đồ
Trong mô hình này, bạn tạo ra một bảng duy nhất để lưu trữ dữ liệu. Mỗi hàng đại diện cho một nút trong cây. Thêm vào quan trọng là một cột, thường được đặt tên làparent_id hoặc ancestor_id, lưu trữ định danh duy nhất của nút cha. Nếu một nút nằm ở đầu phân cấp, cột này sẽ chứa giá trị null.
Xét một bảng choBộ phận:
- id: Khóa chính duy nhất cho bộ phận.
- name: Tên hiển thị của bộ phận.
- parent_id: Mã của phòng ban cấp trên (có thể để trống đối với cấp cao nhất).
✅ Ưu điểm
- Đơn giản:Cấu trúc dữ liệu trực quan và dễ hiểu đối với các nhà phát triển và quản trị viên cơ sở dữ liệu.
- Tính linh hoạt:Di chuyển một nhánh cây là điều đơn giản; bạn chỉ cần cập nhật
parent_idcủa nút gốc nhánh cây đó. - Chuẩn hóa:Nó tuân thủ tốt dạng chuẩn hóa thứ ba (3NF) vì dữ liệu không bị lặp lại.
❌ Nhược điểm
- Độ phức tạp truy vấn:Lấy tất cả các nút con đòi hỏi truy vấn đệ quy hoặc xử lý ở phía ứng dụng.
- Hiệu suất:Việc duyệt sâu có thể chậm nếu không có chiến lược chỉ mục cụ thể hoặc biểu thức bảng chung đệ quy (CTEs).
- Tính toàn vẹn tham chiếu:Mặc dù khóa ngoại hỗ trợ, nhưng các tham chiếu vòng tròn vẫn có thể xảy ra nếu các ràng buộc không được thực thi nghiêm ngặt.
🌲 Mô hình Tập hợp Lồng ghép
Mô hình Tập hợp Lồng ghép chuyển đổi cấu trúc cây thành một tập hợp các khoảng. Thay vì theo dõi các con trỏ cha, mỗi nút được gán hai số:left và right. Các giá trị này đại diện cho vị trí của nút trong phép duyệt tiền thứ tự của cây.
📐 Cấu trúc lược đồ
Hãy tưởng tượng một cây mà nút gốc là toàn bộ tập hợp. Khi bạn duyệt cây, bạn tăng một bộ đếm. Khi bạn vào một nút, bạn ghi lại giá trị bộ đếm hiện tại làleft. Khi bạn hoàn thành xử lý nút đó và tất cả các nút con của nó, bạn ghi lại bộ đếm làright. Cácright giá trị luôn lớn hơn trái giá trị.
Một Danh mụcbảng sẽ trông như thế này:
- id: Mã định danh duy nhất.
- tên: Tên danh mục.
- lft: Giá trị biên trái.
- rgt: Giá trị biên phải.
✅ Ưu điểm
- Truy xuất nhanh:Lấy một nhánh con là một truy vấn phạm vi đơn giản sử dụng
BETWEENlogic. - Hiệu quả: Hiệu suất đọc vượt trội hơn so với danh sách kề đối với các cây lớn, sâu.
❌ Nhược điểm
- Chi phí ghi:Chèn hoặc di chuyển một nút là tốn kém. Bạn phải cập nhật các giá trị
lftvàrgtcủa nhiều nút khác để duy trì tính toàn vẹn của các khoảng cách. - Độ phức tạp: Logic rất khó triển khai và gỡ lỗi mà không có hỗ trợ thư viện chuyên dụng.
🛣️ Đếm đường đi và các đường đi được tạo sẵn
Các phương pháp đếm đường đi lưu trữ nguồn gốc của một nút dưới dạng chuỗi hoặc danh sách có dấu phân cách. Cách tiếp cận này thường được gọi là mẫu Đường đi được tạo sẵn. Nó kết hợp sự đơn giản của danh sách kề với tính dễ đọc của đường đi.
📐 Cấu trúc lược đồ
Trong mô hình này, mỗi bản ghi lưu trữ đường đi đầy đủ từ gốc. Ví dụ, trong mô hình hệ thống tệp, một tệp có thể có chuỗi đường dẫn như/home/user/documents/report.txt. Trong cơ sở dữ liệu, điều này thường được lưu dưới dạng chuỗi có dấu phân cách trong cột, ví dụ như1/5/12/.
Bảng bao gồm:
- id: Khóa chính.
- path: Một chuỗi đại diện cho nguồn gốc.
- depth: Một số nguyên cho biết nút nằm ở độ sâu bao nhiêu cấp.
✅ Ưu điểm
- Duyệt dễ dàng: Bạn có thể tìm thấy tất cả các nút con bằng cách khớp tiền tố đường dẫn.
- Dễ đọc: Dữ liệu dễ đọc bởi con người và dễ gỡ lỗi.
- Sắp xếp: Sắp xếp theo chuỗi đường dẫn thường cho ra thứ tự cây đúng một cách tự nhiên.
❌ Nhược điểm
- Tốn không gian lưu trữ: Các đường dẫn dài có thể tiêu tốn không gian lưu trữ đáng kể.
- Phân tích chuỗi: Các truy vấn thường yêu cầu các hàm thao tác chuỗi, điều này có thể chậm hơn so với so sánh số nguyên.
📊 Phân tích so sánh
Việc chọn mô hình phù hợp phụ thuộc rất nhiều vào tỷ lệ đọc/ghi của bạn và độ sâu của cấu trúc phân cấp. Bảng sau đây nêu rõ đặc điểm của từng phương pháp.
| Tính năng | Danh sách kề | Tập hợp lồng ghép | Đường đi thực tế |
|---|---|---|---|
| Hiệu suất đọc | Thấp đến trung bình | Cao | Trung bình đến cao |
| Hiệu suất ghi | Cao | Thấp | Trung bình |
| Độ phức tạp triển khai | Thấp | Cao | Trung bình |
| Hỗ trợ cây sâu | Có | Có | Có (với giới hạn) |
| Logic truy vấn | Đệ quy | Quét phạm vi | Phù hợp tiền tố |
⚙️ Các yếu tố xem xét hiệu suất
Khi mô hình hóa cấu trúc phân cấp, bạn cần xem xét cách động cơ cơ sở dữ liệu xử lý dữ liệu. Các chiến lược chỉ mục đóng vai trò then chốt bất kể mô hình nào được chọn.
- Danh sách kề: Chỉ mục cột
parent_idmột cách nặng nề. Điều này cho phép cơ sở dữ liệu nhanh chóng tìm thấy tất cả các nút con của một nút cụ thể mà không cần quét toàn bộ bảng. - Tập hợp lồng ghép: Chỉ mục cả hai
lftvàrgt. Chỉ mục kết hợp có thể tối ưu hóa đáng kể các truy vấn phạm vi. - Đường dẫn đã được tạo sẵn: Chỉ mục cột
pathcột. Tùy thuộc vào cơ sở dữ liệu, chỉ mục tiền tố có thể hữu ích để lọc các nhánh con.
🛠️ Bảo trì và Cập nhật
Các mô hình dữ liệu không phải là tĩnh. Khi tổ chức của bạn phát triển, cấu trúc phân cấp của bạn sẽ thay đổi. Di chuyển một nút từ nhánh này sang nhánh khác là thao tác phổ biến, ảnh hưởng khác nhau đến từng mô hình.
🔄 Di chuyển nút
Trong mô hình Danh sách kề, việc di chuyển một nút là một câu lệnh cập nhật duy nhất. Bạn thay đổi parent_id của nút gốc của nhánh con. Tuy nhiên, bạn phải đảm bảo không tạo ra các tham chiếu vòng.
Trong mô hình Bộ đặt lồng ghép mô hình, việc di chuyển một nút là phức tạp. Nó bao gồm việc tính toán lại các giá trị lft và rgt cho tất cả các nút trong nhánh con đích để tạo chỗ cho nút bị di chuyển. Đây thường là một thao tác giao dịch bao gồm nhiều cập nhật bảng.
Trong mô hình Đường dẫn đã được tạo sẵn mô hình, bạn cập nhật chuỗi đường dẫn của nút bị di chuyển và tất cả các nút con của nó. Điều này đòi hỏi cập nhật đường dẫn cho từng nút con, có thể là thao tác ghi nặng đối với các cây lớn.
🎯 Các thực hành tốt nhất cho mô hình hóa dữ liệu
Để đảm bảo sơ đồ ERD của bạn vẫn dễ bảo trì và hiệu suất cao, hãy tuân theo các hướng dẫn này khi triển khai các cấu trúc phân cấp.
- Sử dụng quy ước đặt tên rõ ràng: Tránh sử dụng các tên chung chung như
col1. Sử dụngparent_id,ancestor_id,lft, hoặcrgtmột cách rõ ràng. - Thực thi các ràng buộc: Sử dụng các ràng buộc cơ sở dữ liệu để ngăn chặn các tham chiếu vòng. Một nút không thể là tổ tiên của chính nó.
- Giới hạn độ sâu: Mặc dù về mặt kỹ thuật là khả thi, nhưng các cấu trúc phân cấp quá sâu (ví dụ: nhiều hơn 10 cấp) thường cho thấy một lỗi thiết kế. Hãy cân nhắc làm phẳng cấu trúc nếu có thể.
- Tài liệu lựa chọn: Vì các mẫu này không phải là tính năng chuẩn SQL, hãy ghi rõ mẫu nào được sử dụng trong tài liệu sơ đồ cơ sở dữ liệu.
- Xem xét các phương pháp kết hợp: Một số hệ thống kết hợp danh sách kề với đường dẫn được vật chất hóa để cân bằng hiệu suất đọc và ghi.
🧠 Chọn chiến lược phù hợp
Không có câu trả lời ‘đúng’ duy nhất cho mọi tình huống. Quyết định phụ thuộc vào các yêu cầu cụ thể của ứng dụng của bạn.
- Chọn danh sách kề nếu: Dữ liệu của bạn thay đổi thường xuyên, và độ sâu phân cấp ở mức trung bình. Đây là lựa chọn mặc định an toàn nhất cho phần lớn ứng dụng tổng quát.
- Chọn tập hợp lồng ghép nếu: Bạn có ứng dụng trọng tải đọc cao, nơi dữ liệu hiếm khi được di chuyển, và bạn cần truy xuất các cây con lớn một cách nhanh chóng.
- Chọn đường dẫn được vật chất hóa nếu: Bạn cần các đường dẫn dễ đọc cho con người (như URL) và độ sâu phân cấp tương đối nông.
Hiểu rõ những chi tiết cấu trúc này giúp bạn thiết kế các cơ sở dữ liệu có thể mở rộng. Bằng cách chọn mẫu phù hợp cho sơ đồ quan hệ thực thể của bạn, bạn đảm bảo dữ liệu luôn nhất quán, dễ truy cập và hiệu quả trong suốt vòng đời của hệ thống.