











在現代資料架構中,資訊被擷取的速度經常決定應用程式的可用性。雖然硬體升級與快取策略扮演著重要角色,但效能的基礎在於資料結構本身。具體而言,實體關係模型(ERMs)的設計決定了資料庫引擎能多有效率地遍歷、連接與聚合資料。一個優化的資料結構不僅僅是組織資訊;它還能引導查詢優化器走向更快的執行路徑。 📉
本指南探討資料結構設計背後的技術機制,以及其與查詢效能的直接關聯。我們將檢視規範化程度、關係基數與索引策略如何在查詢執行計畫中相互作用。透過理解這些動態,開發人員與資料庫架構師能夠建構出可擴展且不犧牲完整性或速度的系統。
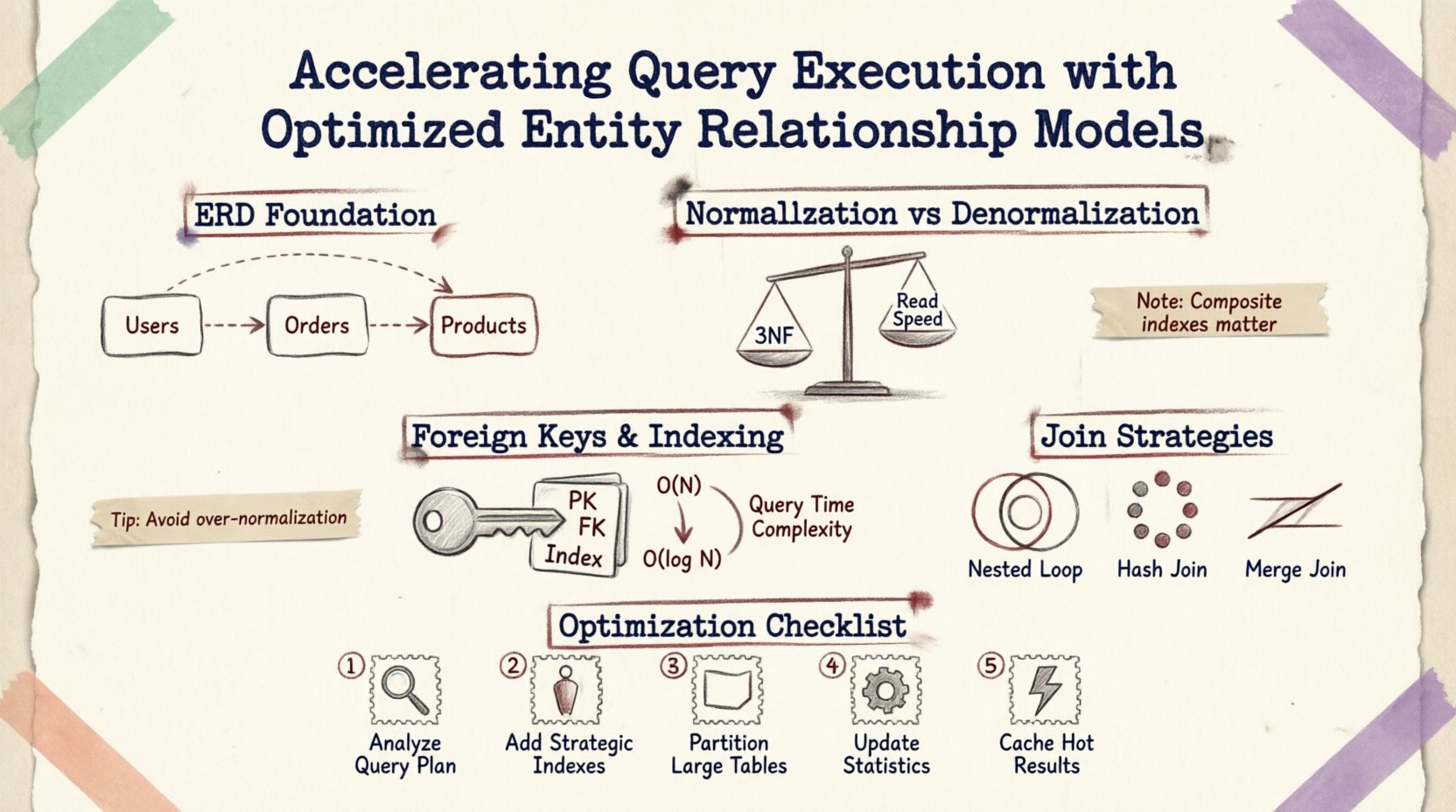
理解基礎:ERD 與效能 🗃️
實體關係圖不僅是文件化的視覺輔助工具;它更是實體儲存與取用邏輯的藍圖。表與表之間每條繪製的線,都代表一個外鍵約束、一次連接操作或一項資料完整性規則。當提交查詢時,資料庫引擎會解讀這些關係,以建構執行計畫。
考慮一個簡單的查詢,要求取得使用者訂單與產品細節。引擎必須:
- 定位
Users表。 - 依照外鍵前往
Orders表。 - 連接
OrderItems表。 - 到達
Products表,透過另一個關係。
每一步都涉及 I/O 操作與 CPU 周期。如果關係定義不佳,引擎可能被迫進行全表掃描或巢狀迴圈連接,導致效能呈指數級下降。優化 ERD 可以減少資料從磁碟到記憶體之間的傳輸距離。
規範化與反規範化:尋找平衡點 ⚖️
規範化是組織資料以減少冗餘並提升完整性的一種過程。雖然對一致性至關重要,但過度規範化會導致資料分散在許多小型表格中,需要複雜的連接操作,從而拖慢讀取密集型作業。
深度規範化的代價
當資料結構被規範化至第三範式(3NF)時,資料會以最原子化的狀態儲存。這能最小化儲存空間並減少更新異常。然而,取得相關資料通常需要遍歷多個外鍵。
- 連接開銷: 連接鏈中的每一個額外表格都會增加查詢計畫的複雜度。
- 鎖競爭: 存取多個表格會增加行級鎖定衝突的可能性。
- CPU 使用率: 資料庫引擎必須合併來自不同表格的結果集。
何時應反規範化
反規範化會引入冗餘以優化讀取效能。這在分析處理或高流量報表環境中經常是必要的。
- 讀取密集型工作負載: 如果寫入次數相對於讀取次數較少,新增一個反規範化的欄位可以省略連接操作。
- 預計算的聚合資料: 將總計值(例如,
total_order_value)儲存在使用者資料表中,可避免每次請求都重新計算總和。 - 水平分割: 將經常存取的資料放在一起,可提升快取的局部性。
然而,反規範化需要謹慎管理,以防止資料不一致。應用程式邏輯必須確保當來源資料變更時,冗餘資料也同時更新。
外鍵與索引策略 🔑
外鍵約束可確保參考完整性,但會帶來效能成本。資料庫必須在允許插入或更新前,驗證某個資料表中的值是否在另一個資料表中存在。優化這些鍵的索引方式至關重要。
外鍵索引
預設情況下,主鍵會自動建立索引。然而,外鍵通常需要明確建立索引,以加速連接操作。若外鍵欄位未建立索引:
- 資料庫必須對子資料表執行完整掃描,以尋找相符的資料列。
- 連接操作會顯著變慢,特別是當資料表規模成長至數百萬列時。
- 刪除時的參考完整性檢查會變得昂貴。
一個正確建立索引的外鍵,可讓資料庫使用索引搜尋而非掃描,將複雜度從 O(N) 降低至 O(log N)。
關係的複合索引
當多個欄位共同定義一個關係時,複合索引可能比單獨索引更有效。例如,若查詢根據 user_id 和 created_at 在訂單資料表中進行過濾時,對這兩個欄位建立複合索引,可確保資料庫引擎能快速定位資料,而無需掃描無關的記錄。
連接策略與執行計畫 🔍
ERD 的結構會影響查詢優化器選擇的連接演算法。了解這些機制有助於設計出偏好高效連接類型的資料庫結構。
| 連接類型 | 最適合使用的情境 | 效能影響 |
|---|---|---|
| 巢狀迴圈連接 | 小結果集或高度選擇性謂詞 | 小數據時快速;大規模掃描時緩慢 |
| 雜湊連接 | 沒有索引的大表 | 記憶體密集;適合未排序資料 |
| 合併連接 | 連接鍵上的已排序輸入 | 若資料已排序,則極快 |
設計ERD以支援已排序輸入或索引查找,可促使優化器選擇更快的連接方式。例如,確保連接鍵被定義為聚集索引的一部分,可促進合併連接的使用。
模式設計中的常見陷阱 🚫
即使經驗豐富的架構師也會犯影響查詢速度的錯誤。早期識別這些模式可避免後續高昂的重構成本。
- 鏈式外鍵: 建立一連串關係,其中表A連結至B,B連結至C,C再連結至D。查詢同時連接四張表時會變得層層嵌套且緩慢。
- 可變長度字串: 使用
VARCHAR用於長度始終固定的鍵,會浪費空間並減慢資料列比較速度。 - 多對多關係缺少關聯表: 嘗試將多個ID儲存在單一欄位中(例如以逗號分隔的值),會阻止正確的索引建立與資料正規化。
- 隱式轉換: 定義父表與子表之間資料類型不匹配,會迫使引擎在執行時轉換值,從而阻止索引的使用。
優化實務步驟 🛠️
為在不重寫整個系統的情況下提升查詢執行效率,請遵循以下結構化步驟:
- 分析查詢模式: 回顧最常見的讀取操作。識別哪些表被最頻繁地連接。
- 檢視索引使用情況: 檢查外鍵或經常過濾的欄位是否缺少索引。
- 優化基數: 確保關係被準確建模(一對一 vs. 一對多)。錯誤的基數會導致不必要的連接。
- 分割大表: 如果表格的資料超過百萬筆,建議根據日期或地區進行分割,以限制每次查詢所掃描的資料量。
- 監控鎖定: 使用監控工具來識別執行時間較長且持有鎖定的查詢,這通常是由於資料結構遍歷效率低下所導致。
儲存與記憶體考量 💾
資料的物理佈局也扮演著重要角色。資料庫引擎將資料儲存在頁面中。如果相關的資料列在物理上彼此接近儲存,則加載資料集所需的磁碟讀取次數會減少。
- 群集: 根據共同的鍵來組織資料,可以提升範圍搜尋的效率。
- 欄式儲存與列式儲存: 對於分析型查詢,欄式儲存可能提供比傳統基於列的模型更佳的壓縮效果與更快的聚合速度。
- 快取: 設計能夠有效快取整個結果集而非單一資料列的資料結構。
關於資料結構演化的最後想法 🔄
資料結構設計並非一蹴可幾的任務。隨著應用程式需求的變動,資料模型也必須持續演進。定期審查資料庫結構,可確保效能維持穩定。實體關係模型的文件應與程式碼庫同步維護,以追蹤變更對系統的影響。
透過專注於資料中的結構完整性與邏輯關係,您將建立一個支援高速查詢執行的基礎。目標並非打造一個靜態系統,而是建立一個能適應負載變動,同時不犧牲使用者預期速度的彈性架構。 📊
優化實體關係模型是一門結合資料庫理論與實際工程技術的專業學問。它需要耐心、分析能力,以及對底層引擎如何處理請求的清晰理解。只要採取正確的方法,效能問題便能被有效管理,資料檢索也能變得順暢無阻。