











隨著資料累積速度加快,資料庫結構的架構成為系統穩定性的關鍵決定因素。當應用程式從以讀取為主的作業轉向以寫入為主的工作負載時,標準的實體關係圖(ERD)通常需要大幅調整。設計高吞吐量系統不僅僅是增加索引這麼簡單,更需要根本性地重新思考資料的結構、連結與儲存方式。本指南探討在壓力下維持效能所必需的架構轉變,同時不犧牲資料完整性。
理解以寫入為主的工作負載 📈
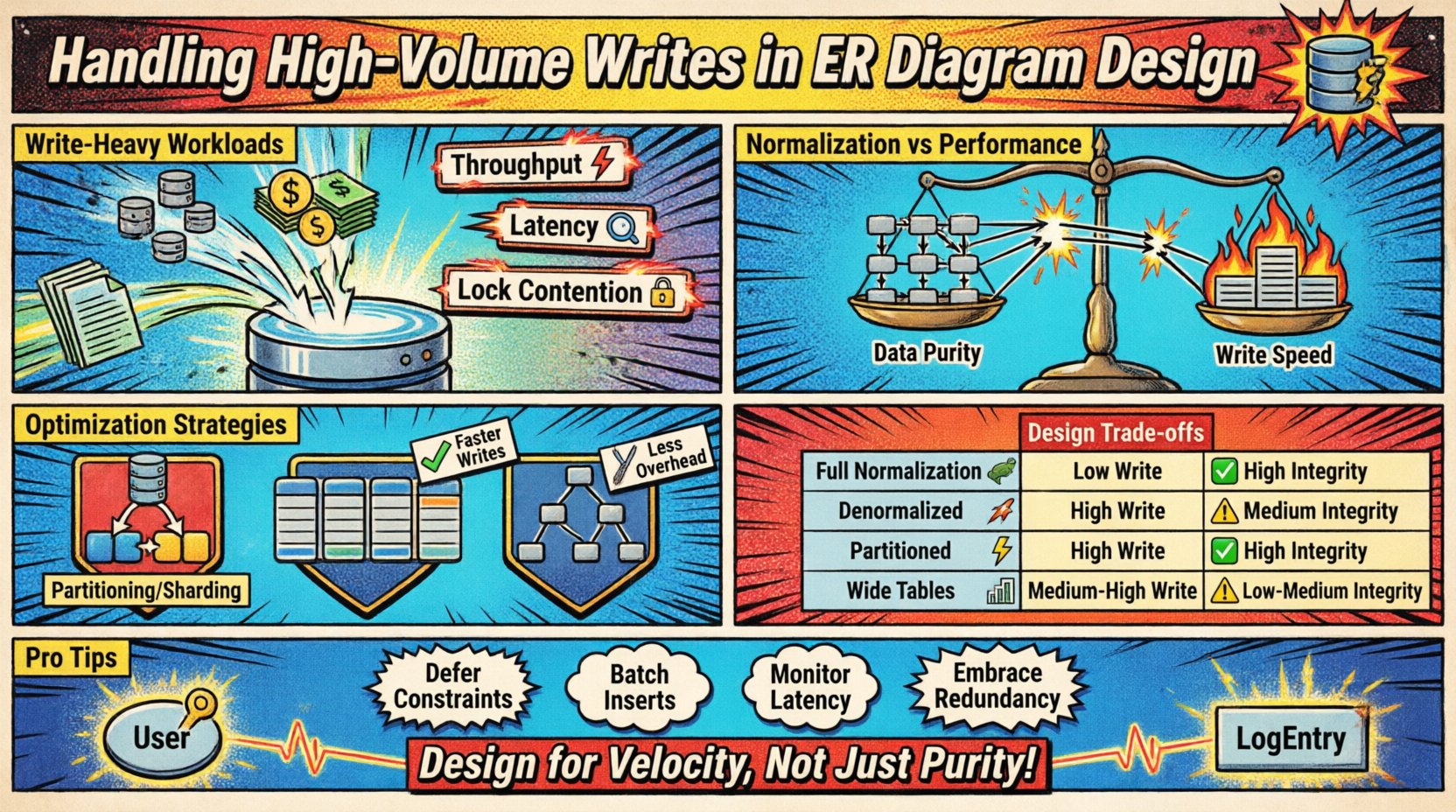
當資料流入速率超過標準正規化技術的處理能力時,就會出現高頻率寫入的情境。這通常發生在記錄系統、物聯網感測器資料流、金融交易帳本或即時分析平台中。主要挑戰在於平衡插入速度與模型一致性要求之間的關係。
- 吞吐量: 每秒處理的寫入作業數量。
- 延遲: 成功持久化一筆記錄所需的時間。
- 鎖競爭: 當多個程序試圖修改相同資料時,對資源產生競爭。
當這些指標下降時,資料結構本身往往是瓶頸。一個為複雜查詢優化而設計的僵化架構,可能在持續更新的壓力下崩潰。因此,最初的ER圖必須考慮資料輸入的速度。
正規化與效能的權衡 ⚖️
傳統資料庫設計鼓勵正規化(1NF、2NF、3NF)以減少冗餘。雖然這能節省儲存空間並確保一致性,但在寫入操作期間會引入額外開銷。每個外鍵關係都需進行查找與連接檢查,以維持參考完整性。
在高頻率環境中,這些檢查變得相當昂貴。考慮在寫入事件期間,多對多關係所帶來的影響:
- 主要資料表必須更新。
- 關聯資料表必須插入一筆新記錄。
- 第二個資料表必須驗證該關係。
- 交易記錄必須記錄所有變更。
每一步都會增加磁碟I/O與CPU週期。為了應付沉重的寫入負載,設計者經常放寬正規化規則。此過程涉及接受資料冗餘,以減少儲存單一資訊單位所需的寫入作業數量。
優化寫入速度的策略 ✍️
存在多種結構性模式可緩解寫入壓力。這些策略著重於最小化每次交易的規模,並降低儲存引擎工作的複雜度。
1. 分區與分片
將大型資料表拆分成較小且更易管理的區塊,可讓資料庫將寫入負載分散至多個實體或邏輯區段。
- 水平分區: 根據某個鍵(例如日期範圍、使用者ID)來分割資料列。
- 垂直分區: 將較少被存取的欄位移至獨立的資料表中。
- 分片: 將資料分散至多個資料庫執行個體中。
此方法可減少必須維護的索引大小,並限制寫入作業期間鎖的範圍。若某一組分片達到飽和,其他分片仍不受影響。
2. 反規範化策略
儲存冗餘資料可讓系統在寫入時避免使用連接操作。例如,當新交易到達時,系統無需每次都從相關資料列計算總和,而是可以直接更新預先計算好的摘要欄位。
- 計算欄位: 直接在資料列中儲存衍生值。
- 物化檢視: 對常見的聚合操作預先計算結果。
- 快取計數器: 為統計資料維護一個獨立的計數器資料表。
雖然這會增加儲存需求,但能顯著降低插入操作的 CPU 成本。
3. 索引策略
索引能加快讀取速度,但會減慢寫入速度。每次插入資料列時,資料庫都必須更新所有相關的索引。在高寫入環境中,索引膨脹會成為主要問題。
- 減少索引數量: 僅對用於過濾或連接的欄位建立索引。
- 部分索引: 僅對經常存取的資料列子集建立索引。
- 避免過度索引: 忽略經常變更的欄位上的索引。
比較設計方法 📑
下表概述了不同結構選擇對寫入效能與資料完整性的影響。
| 策略 | 寫入效能 | 資料完整性 | 儲存成本 | 最佳使用情境 |
|---|---|---|---|---|
| 完全規範化 | 低 | 高 | 低 | 複雜報表、低寫入量 |
| 反規範化 | 高 | 中等 | 高 | 即時資料流,高寫入量 |
| 分割式結構 | 高 | 高 | 中等 | 時間序列資料,大型資料集 |
| 寬表 | 中高 | 中等 | 中等 | NoSQL 模式,稀疏資料 |
處理外鍵與約束 🔗
參考完整性是關聯式設計的基石,但在每次插入時強制執行約束可能會阻塞高速資料流。資料庫引擎必須在接受子資料列之前,驗證所參考的父資料列是否存在。
在資料完整性至關重要但寫入速度至關重要的情境下,可考慮以下調整:
- 延遲約束:在交易結束時驗證關係,而非立即執行。
- 應用層檢查:在將資料傳送至資料庫之前,於應用程式程式碼中驗證關係。
- 軟刪除:將記錄標記為非活躍狀態,而非直接刪除,以保留參考連結且無刪除的額外負擔。
完全移除約束具有風險,但將驗證邏輯移至其他位置有時可提升吞吐量。此決策取決於您的特定工作流程中即時一致性的重要性。
寫入放大與儲存引擎 💾
了解儲存引擎如何處理資料至關重要。許多引擎使用預寫日誌(WAL)來確保資料持久性。這表示每次寫入都會先記錄日誌,再應用至實際的資料檔案。
寫入放大當單一邏輯寫入作業導致多個實際寫入時發生。這在以合併為主的儲存引擎中相當常見。為管理此情況,請:
- 批次插入:將多筆資料列合併為單一交易。
- 順序寫入: 設計資料結構時,應優先考慮順序鍵生成,而非隨機插入。
- 快取: 允許在應用層設置暫時快取,用以排隊寫入作業,再進行刷新。
透過將ERD設計與儲存引擎的優勢對齊,可大幅減少持久化資料所需的實際運作成本。
監控與迭代 🔄
為高寫入量設計的資料結構並非一成不變。隨著流量模式的變化,設計可能需要演進。持續監控寫入延遲與磁碟I/O是必要的。
- 追蹤寫入延遲: 識別突增,以判斷瓶頸所在。
- 監控鎖等待: 檢測造成程序阻塞的競爭點。
- 分析索引使用情況: 移除從未使用的索引,以降低寫入負載。
定期審查ERD,可確保結構持續符合當前的運營需求。若某張特定表格持續在寫入吞吐量上遇到困難,可能需要重新檢視其分割策略或規範化層級。
關鍵考量要點總結 🛠️
為高頻率寫入設計ERD,需要從純粹的資料純粹性轉向系統吞吐量的思維。以下要點總結了必要的行動:
- 審查規範化: 確保每個關係都帶來價值,而非僅僅增加複雜度。
- 計畫分割: 設計鍵結構,以支援輕鬆的水平分割。
- 限制索引: 使寫入路徑盡可能簡潔。
- 接受冗餘: 使用反規範化,以減少插入時的連接依賴。
- 漸進驗證: 在安全的情況下,將約束檢查移出關鍵寫入路徑。
透過應用這些原則,您將建立一個能持續支援成長而不犧牲效能的資料模型。目標並非消除複雜性,而是以支援應用程式速度的方式來管理它。