











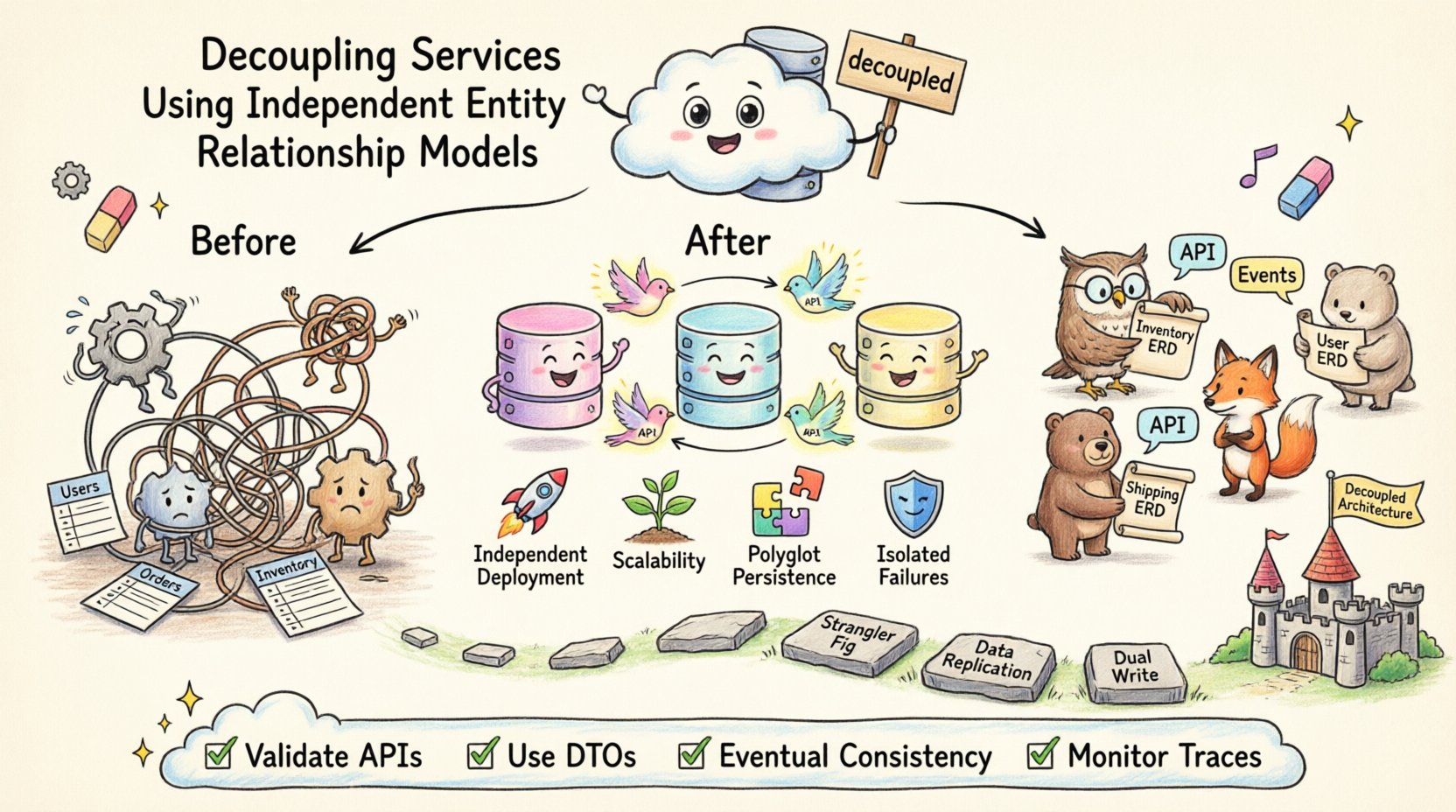
在現代軟體架構中,關注點分離不僅延伸至程式碼邏輯,更深入到資料所有權。當服務共用單一資料庫結構時,它們不可避免地會依賴彼此的內部實作。這種緊密耦合會造成系統脆弱,阻礙部署速度,並使擴展變得複雜。為實現真正的模組化,團隊必須為每個服務邊界採用獨立的實體關係模型。此方法確保資料結構僅對擁有它的服務私有,從而促進系統的韌性和自主性。
🤔 共享資料的挑戰
傳統系統通常依賴於單一資料庫,其中多個應用模組查詢相同的資料表。雖然這簡化了初期開發,但隨著系統擴展,會帶來顯著風險。一個模組的資料需求變更,可能導致依賴相同資料表結構的另一個模組功能中斷。這種現象被稱為共用資料庫反模式.
想像一個情境:使用者服務需要在個人資料表中新增一個欄位。如果訂單服務直接查詢該資料表以取得使用者姓名,此更新可能需要協調部署,或進行影響雙方團隊的資料庫遷移。這種協調開銷會減緩創新速度,並增加生產環境事故的風險。
-
部署依賴:若服務共用結構定義,則無法獨立部署。
-
可擴展性限制:當特定服務需要比其他服務更多的資源時,單一資料庫通常會成為瓶頸。
-
安全風險:直接存取資料表會跳過服務層,可能暴露敏感的資料邏輯。
🗺️ 定義獨立的實體關係模型
獨立的實體關係模型(ERD)為單一服務指派特定的資料結構。這表示該服務掌控自己的資料庫、自己的資料表以及自己的關係。其他服務無法直接存取這些資料表,而是透過定義好的介面(如 API 或訊息佇列)進行互動。
這種架構風格通常被稱為服務對應資料庫。它將資料所有權與業務能力對齊。例如,庫存服務管理庫存水準,而配送服務管理配送地址。任一服務都不應持有對另一服務內部資料表的外鍵參考。
此過程包含:
-
識別邊界:判斷哪些資料屬於哪個業務能力。
-
設計本地結構:建立僅支援該服務特定需求的 ERD。
-
定義介面:建立服務之間資料交換的方式,而不暴露內部結構。
📈 資料結構隔離的主要優勢
採用獨立的 ERD 能改變團隊管理複雜性的方式。它將焦點從集中式控制轉向分散式自主。每個團隊都能優化其資料儲存策略,而不必擔心對整體系統造成影響。
|
面向 |
共用資料庫模型 |
獨立 ERD 模型 |
|---|---|---|
|
部署 |
協調性高,風險高 |
獨立且頻繁 |
|
可擴展性 |
僅水平擴展(叢集) |
每個服務獨立垂直擴展 |
|
技術 |
單一資料庫類型 |
多語言持久化 |
|
失敗域 |
單點故障 |
故障隔離 |
🔗 設計鬆散耦合
當服務無法直接與彼此的資料庫通訊時,必須透過 API 進行溝通。這需要仔細設計服務之間的合約。API 變成唯一的共享合約。只要 API 合約保持穩定,底層資料模型的變動就不會影響消費者。
API 版本控制: 由於資料模型會演進,API 必須支援版本控制。這讓舊版客戶端仍可運作,同時新版客戶端可採用更新的結構。
資料傳輸物件 (DTOs): 不要直接暴露實體物件。建立專門的 DTO,僅攜帶消費者所需的資料。這可防止內部變更外洩。
-
驗證: 在 API 边界進行輸入驗證,而不僅僅在資料庫層級。
-
冪等性: 確保操作可安全重複執行,而不會造成重複記錄。
-
文件: 維護所有資料交換格式的清晰文件。
⚖️ 處理交易與一致性
解耦過程中最具挑戰性的問題之一是維持資料完整性。在共用資料庫中,交易可輕鬆跨越多個資料表。在分散式系統中,單一邏輯交易可能跨越多個服務。這被稱為分散式交易問題.
為解決此問題,團隊通常採用最終一致性 模式。系統不會立即確保資料在所有地方完全相同,而是確保資料會隨著時間逐漸達成一致。這透過非同步訊息傳遞來實現。
貪婪模式: 貪婪是一系列本地交易的組合。每個交易都會更新資料庫,並發佈事件以觸發下一個交易。如果某一步驟失敗,就會執行補償交易來撤銷先前的變更。
-
出站模式: 將事件寫入與主要資料變更並列的本地資料表中。背景程序會發佈這些事件,確保資料不會遺失。
-
幂等消費者: 訊息處理器必須能妥善處理重複訊息。
-
補償動作: 為每一項前進動作定義明確的回滾邏輯。
🚚 迁移策略
從共用資料庫遷移至獨立的實體關係圖(ERD)是一項重大任務。這需要分階段進行以降低風險。匆忙遷移可能導致資料遺失或服務中斷。
索敵樹模式: 逐步將功能遷移至新服務。從特定功能開始,例如使用者通知。為該功能建立具有獨立 ERD 的新服務。將流量導向新服務,同時保持舊系統運作。
資料複製: 在過渡期間,您可能需要保持舊資料庫與新資料庫之間的資料同步。這讓新服務能暫時從舊系統讀取資料,直到其自身資料庫填滿為止。
雙寫: 在遷移期間,同時寫入舊資料庫與新資料庫。在停用舊寫入之前,先確認新服務運作正常。
🔍 監控與維護
使用獨立的資料儲存後,監控變得更加複雜。您不再僅僅查看單一資料庫健康狀態儀表板,而必須整合來自多個來源的紀錄與指標。
分布式追蹤: 實作追蹤功能,以追蹤請求在不同服務間傳遞的過程。這有助於識別是哪個服務造成延遲或錯誤。
資料結構註冊表: 維護 API 合約的註冊表。這確保任何資料模型的變更都經過審查與批准後才可部署。
-
警報: 設定複製延遲與訊息佇列積壓的警報。
-
容量規劃: 監控每個服務的儲存空間成長,以避免產生意外成本。
-
備份策略: 確保每個服務都有獨立的備份與復原計畫。
🛠️ 常見陷阱與避免方法
即使有穩固的計畫,團隊在執行時仍經常遇到問題。了解這些常見錯誤可以節省大量時間和精力。
-
隱藏的耦合:即使資料表位於不同的結構中,也應避免使用資料庫檢視或共用資料表。應禁止直接存取資料庫。
-
過度碎片化:不要為每個微小功能都建立新的資料庫。應將相關實體歸類為邏輯服務。
-
忽略延遲:網路呼叫比本地查詢慢。設計 API 時應盡量減少往返次數。
-
複雜查詢:避免跨服務的連接操作。若需來自多個服務的資料,應分別查詢,並在應用層合併結果。
🧱 最後的想法
使用獨立的實體關係模型來解耦服務,是一項具有戰略意義的決策,長期而言將帶來回報。這需要設計上的紀律,以及願意管理分散式複雜性的態度。然而,結果是一個更易於擴展、更具容錯能力,且更快速演進的系統。透過掌握自身資料,服務能夠獲得創新所需的自主性,無需持續協調。
首先識別系統中最重要的邊界。先為這些服務隔離資料。在進行過程中不斷優化 API 合約與通訊模式。這種逐步進行的方式,能在邁向完全解耦架構的同時確保穩定性。