











設計一個穩健的資料庫,遠在第一個查詢執行之前就已開始。它從藍圖開始:實體關係圖(ERD)。雖然許多開發人員專注於表格建立與欄位類型,但真正的效能引擎在於索引如何與您的資料模型對齊。索引不僅僅是設定選項;它是您邏輯關係的實際體現。
當您設計ERD時,您定義了資料的基數與連接性。這些結構性選擇決定了最有效的索引策略。一對一的關係需要與多對多關聯不同的處理方式。忽略這些細節通常會導致查詢速度緩慢、過度的I/O操作以及儲存碎片化。本指南探討如何將您的ERD轉化為高效率的索引模式,而無需依賴特定廠商工具。
🔑 理解基礎:ERD與索引
ERD不僅僅是視覺輔助工具;它是應用程式邏輯與儲存引擎之間的合約。在實體之間繪製的每一條線都代表資料庫必須強制執行的約束。索引的作用在於加速這些約束的強制執行,以及跨約束的資料檢索。
將儲存層視為圖書館。若無索引,尋找一本書需要掃描每一排書架(全表掃描)。索引就如同目錄卡。然而,若目錄卡放置不當——例如當作者是主要搜尋關鍵字時卻按類型排列——將使系統效率低下。您的ERD告訴您作者與類型是誰,以及哪些關係最為重要。
關鍵考量包括:
- 基數:高基數欄位(唯一值)最能從索引中受益。
- 連接頻率:經常被連接的表格,其外鍵需有特定的索引。
- 寫入量:每個索引都會增加插入與更新操作的開銷。
- 查詢模式:您如何過濾?如何排序?ERD會暗示答案。
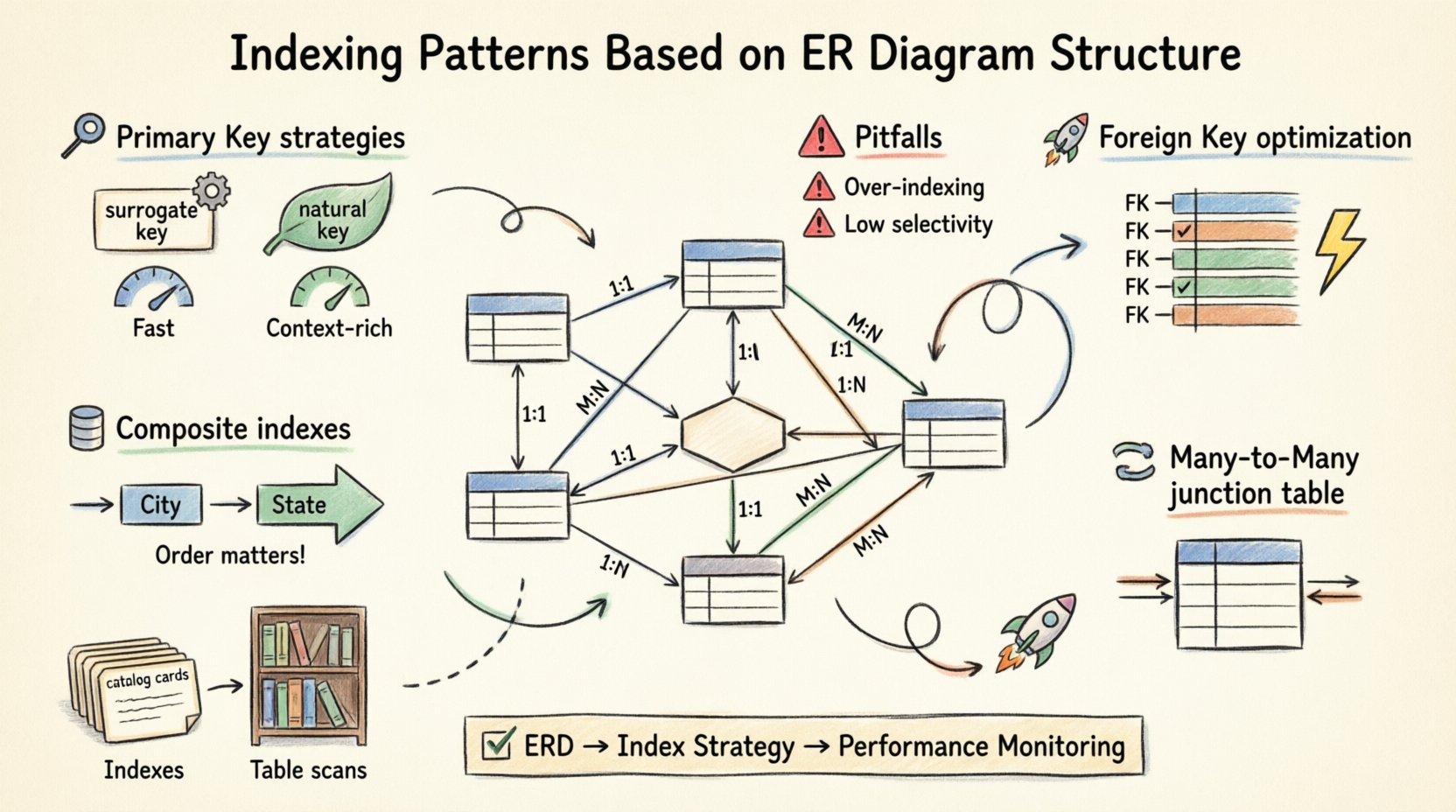
🏗️ 主鍵索引策略
主鍵(PK)是每張表格的骨幹。它確保唯一性,並在許多系統中提供資料儲存的群集機制。將您的索引與PK定義對齊,是第一步。
1. 代理鍵與自然鍵
在代理鍵(自動遞增ID)與自然鍵(如電子郵件或社會安全號碼)之間選擇,會顯著影響索引效能。
- 代理鍵: 這些非常適合群集。它們短小、單調遞增且連續。這能最小化寫入時的頁面分割與碎片化。📈
- 自然鍵: 雖然語意上有意義,但可能長度不一、長度可變,或容易變更。索引它們可能導致索引體積更大,且比基於整數的鍵查詢速度更慢。
2. 群集索引的影響
在大多數架構中,主鍵定義了群集索引。這表示實際的資料列會按照鍵的順序物理儲存。如果您的ERD顯示查詢經常根據特定自然屬性過濾,您可能需要重新考慮主鍵定義,或接受群集索引僅針對某種查詢類型進行優化,而其他查詢則由次級索引處理。
🔗 外鍵優化
外鍵(FK)定義了表格之間的關係。若未建立索引,它們是最常見的效能瓶頸來源。當您連接兩個表格時,資料庫引擎必須根據FK欄位匹配資料列。若無索引,此操作將退化為巢狀迴圈掃描,對大型資料集而言計算成本極高。
1. 為外鍵欄位建立索引
永遠在子表格的外鍵欄位上建立索引。這讓引擎能快速定位相關資料列,而無需掃描整個表格。
| 情境 | 索引需求 | 性能影響 |
|---|---|---|
| 一對多(子表) | 在子表中索引外鍵 | 可快速查找父資料 |
| 多對一(父表) | 在父表中索引主鍵(通常為預設) | 標準主鍵行為 |
| 級聯刪除 | 索引外鍵 + 父表主鍵 | 防止刪除時鎖定整個表格 |
2. 複合外鍵
有時,一個關係依賴於多個欄位(例如,來自父表的複合鍵)。在這種情況下,您必須在子表中建立一個複合索引,其欄位順序和內容需與父鍵一致。若索引中的欄位順序與父鍵不匹配,將導致該索引在連接操作中失效。
🔀 處理多對多關係
多對多(M:N)關係透過一個關聯表來解決。該表格包含指向兩個父表的外鍵。在此處的索引策略對性能至關重要。
考慮這樣一種情境:學生註冊於課程。關聯表將它們連結起來。要找出某位學生的所有課程,您需要高效地查詢關聯表。
- 雙向索引:您應獨立地為兩個外鍵欄位建立索引。這允許您從任一側查詢關係(學生 → 課程 或 課程 → 學生),而無需進行全表掃描。
- 複合索引:如果您的查詢總是用來取得特定學生的課程,則在(學生ID、課程ID)上建立複合索引,比使用兩個獨立索引更高效。它能在單次查找中覆蓋搜尋條件。
📊 複合索引與覆蓋索引
並非所有查詢都僅依賴單一欄位過濾。複雜查詢通常涉及多個條件。這正是複合索引發揮作用之處。複合索引是在多個欄位上建立的單一索引。
1. 欄位順序至關重要
複合索引中欄位的順序並非任意。資料庫引擎只能利用索引到等值條件停止的位置為止。例如,如果您建立(城市、州)的索引,則依城市過濾的查詢會使用該索引;但僅依州過濾的查詢很可能會忽略它。
2. 覆蓋索引
覆蓋索引包含滿足查詢所需的全部欄位,包括 SELECT 列表。這使得資料庫可以直接從索引樹中取得資料,而無需存取主表(堆疊)。這對於讀操作密集的場景是一項巨大的性能優勢。
⚠️ 常見陷阱與最佳實務
即使擁有完美的ERD,實作錯誤仍可能導致效能下降。以下是將結構轉換為儲存時應避免的常見陷阱。
- 過度索引:每個索引都會消耗磁碟空間並減慢寫入作業。僅對經常查詢或用於約束的欄位建立索引。
- 低選擇性:對低基數欄位(例如布林值「is_active」旗標)建立索引通常效率不高。優化器可能認為全表掃描比跳轉至索引更快。
- 忽略NULL值:索引根據資料庫引擎的不同,處理NULL值的方式也不同。請確保您的查詢邏輯能考慮到在特定設定下NULL值的索引方式。
- 碎片化:隨著時間推移,索引會產生碎片化。需定期維護以保持最佳效能。
🛠️ 性能監控與維護
一旦您的索引策略建立完成,監控就至關重要。無法優化您無法衡量的事物。定期檢視查詢執行計畫,確認您的索引是否被有效使用。
1. 分析執行計畫
注意「索引掃描」與「索引搜尋」等作業。搜尋效率高,掃描則不然。若在大型表格上看到全表掃描,應根據實際查詢模式重新檢視您的索引策略。
2. 追蹤索引使用狀況
有時索引被建立卻從未使用,成為無用負擔。定期審計索引使用統計資料,以識別可刪除的未使用索引,進而提升寫入效能。
3. 資料增長考量
隨著資料量增長,維護成本也隨之增加。一個在1萬筆資料下運作良好的索引,可能在1000萬筆資料時成為瓶頸。隨著資料集擴大,應重新評估由ERD衍生的索引模式。同時,可能也需要搭配使用分割策略。
🔄 對齊總結
將您的索引策略與ERD結構對齊是一個持續的過程。這需要理解設計中定義的資料關係,並將其轉化為實體儲存的優化。
- 主鍵:用於資料群集與唯一性。
- 外鍵:建立索引以提升連接效能。
- 關聯表:針對M:N關係建立雙向索引。
- 查詢模式:根據特定篩選順序調整複合索引。
透過尊重ERD的結構完整性,您將建立一個可順利擴展的資料庫。您能避免隨意索引的常見陷阱,並確保隨著應用程式演進,資料仍保持可存取且高效能。這種紀律嚴明的方法可確保資料庫支援您的業務邏輯,而不會成為瓶頸。🚀