











Projektowanie bazy danych to ćwiczenie w równowadze. Wymaga ono strukturyzowania danych w taki sposób, aby odzwierciedlały one rzeczywiste relacje, jednocześnie utrzymując wydajność i integralność. Powszechną pułapką w tym procesie jest wprowadzanie zależności cyklicznych w diagramach relacji encji (ERD). Takie pętle powstają, gdy łańcuch relacji kluczy obcych w końcu wskazuje z powrotem na encję początkową. Choć wydają się logiczne w izolacji, takie struktury stwarzają istotne wyzwania dla zarządzania danymi, optymalizacji zapytań i stabilności systemu.
Rozwiązanie tych problemów wymaga głębokiego zrozumienia teorii relacyjnej oraz starannego planowania architektonicznego. Niniejszy przewodnik omawia mechanizmy zależności cyklicznych, ich wpływ na zdrowie bazy danych oraz sprawdzone strategie przekształcania schematów w celu osiągnięcia optymalnej wydajności.
🧩 Zrozumienie zależności cyklicznych w diagramach ER
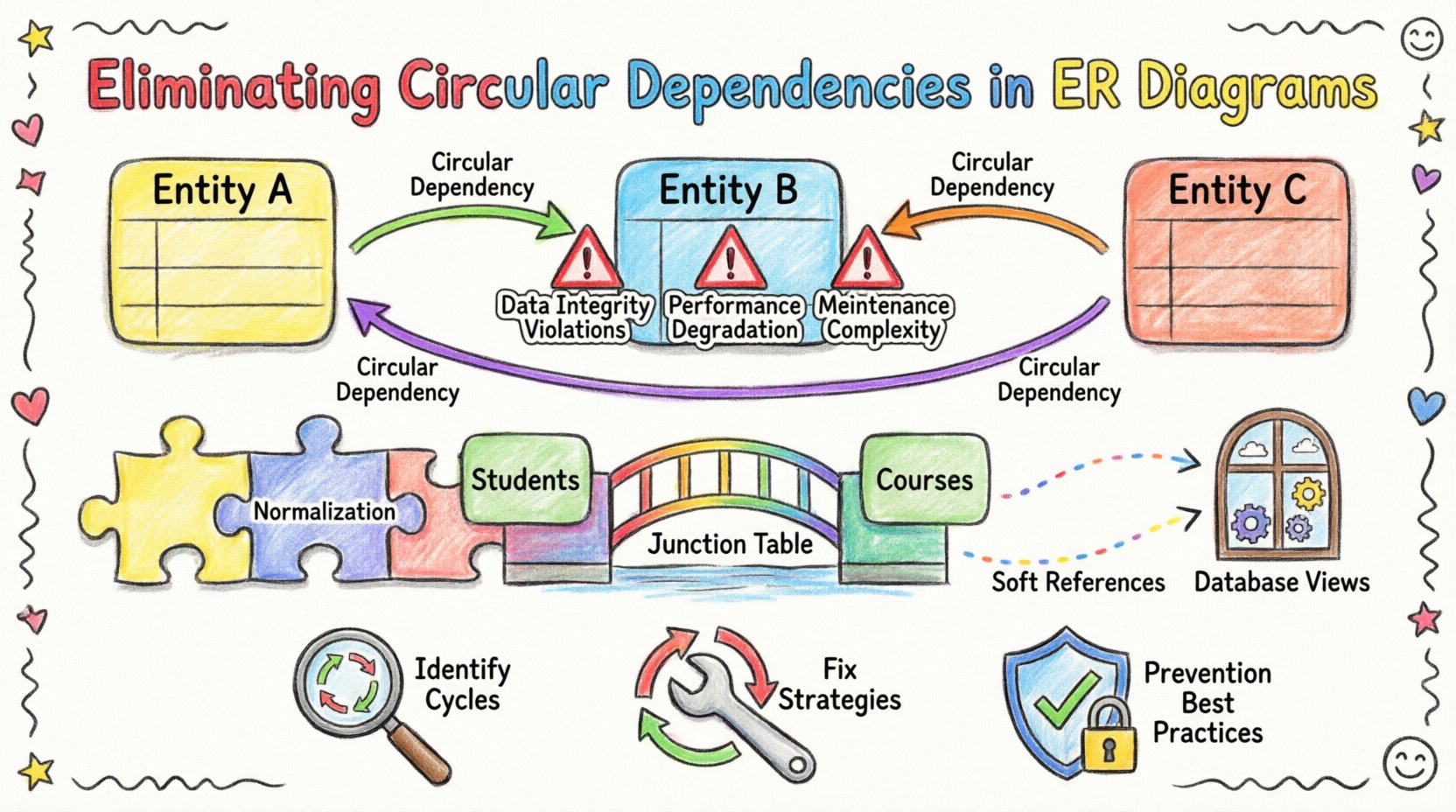
W standardowym modelu relacyjnym ograniczenie klucza obcego tworzy połączenie od tabeli potomnej do tabeli nadrzędnej. To połączenie zapewnia integralność referencyjną, gwarantując, że dane w tabeli potomnej odpowiadają poprawnym wpisom w tabeli nadrzędnej. Zależność cykliczna powstaje, gdy ten łańcuch nie kończy się czysto. Zamiast tego encja A odwołuje się do encji B, która odwołuje się do encji C, która w końcu odwołuje się do encji A.
Rozważ sytuację związaną z hierarchiczną strukturą. Jeśli każdy węzeł w drzewie musi znać swoje rodzice i dzieci, dwukierunkowe relacje mogą łatwo tworzyć pętle. Bez starannego zarządzania silnik bazy danych nie może rozwiązać kolejności operacji podczas wstawiania lub usuwania danych.
Rodzaje odwołań cyklicznych
- Cykle bezpośrednie:Encja A ma klucz obcy do encji B, a encja B ma klucz obcy z powrotem do encji A. Zdarza się to często w dwukierunkowych relacjach, gdzie obie strony śledzą się nawzajem.
- Cykle pośrednie: Łańcuch trzech lub więcej encji tworzy pętlę. Na przykład: A → B → C → A. Są one trudniejsze do wykrycia wizualnie w złożonych schematach.
- Pętle samodzielne:Encja odwołuje się do samej siebie. Choć jest to powszechne w danych hierarchicznych (np. tabela pracowników, gdzie menedżer jest również pracownikiem), niepoprawna implementacja może prowadzić do nieskończonej rekurencji.
⚠️ Skutki nieusuniętych pętli
Pozostawienie zależności cyklicznych nierozwiązanymi to nie tylko kwestia teoretyczna. Przynosi to rzeczywiste ryzyko dla warstwy aplikacji oraz samego silnika bazy danych.
1. Naruszenia integralności danych
Gdy silnik bazy danych próbuje wstawić dane do pętli, musi określić kolejność operacji. Jeśli A wymaga istnienia B, a B wymaga istnienia A, żadna z nich nie może zostać utworzona najpierw. Powoduje to naruszenia ograniczeń. Choć niektóre systemy baz danych pozwalają odłożyć sprawdzanie ograniczeń, poleganie na tej funkcji często ukrywa błędy logiczne.
2. Degradacja wydajności
Zapytania przemieszczające się po ścieżkach cyklicznych mogą stać się nieefektywne. Operacje połączeń w pętli mogą spowodować, że optymalizator wybierze nieoptymalne plany wykonania. W najgorszych przypadkach zapytania rekurencyjne przeznaczone do przemieszczania się po hierarchii mogą wejść w nieskończoną pętlę, zużywając zasoby CPU i pamięci, aż połączenie zostanie przerwane.
3. Złożoność utrzymania
Modyfikowanie schematu z zależnościami cyklicznymi jest ryzykowne. Usunięcie tabeli w pętli może się nie powieść, jeśli klucze obce są aktywne. Operacje usuwania kaskadowego mogą wywołać nieoczekiwane reakcje łańcuchowe. Programiści często muszą pisać logikę na poziomie aplikacji, aby obejść ograniczenia bazy danych, co przenosi obciążenie integralności z źródła prawdy.
🔍 Identyfikacja zależności cyklicznych
Zanim naprawisz problem, musisz go znaleźć. W małych diagramach wystarcza wizualna inspekcja. W systemach typu enterprise z setkami tabel ręczne śledzenie jest podatne na błędy. Użyj poniższych technik do audytu swojego schematu.
- Analiza grafu:Traktuj diagram ER jako graf skierowany. Węzły reprezentują tabele, a krawędzie – klucze obce. Pętla istnieje, jeśli ścieżka prowadzi z powrotem do węzła początkowego.
- Drzewa zależności: Generuj drzewo zależności dla każdej tabeli. Jeśli tabela pojawia się jako własny przodek w drzewie, istnieje pętla.
- Zapytania do tabel systemowych: Większość systemów zarządzania bazami danych przechowuje metadane kluczy obcych w katalogach systemowych. Napisz zapytania, które przeszukują te relacje programowo.
🛠️ Strategie rozwiązywania
Po identyfikacji zależności cykliczne muszą zostać rozwiązane. Celem jest zachowanie relacji logicznej bez tworzenia pętli fizycznej. Poniżej przedstawiono główne metody osiągania tego celu.
1. Normalizuj schemat
Normalizacja to proces organizowania danych w celu zmniejszenia nadmiarowości i poprawy integralności. Często zależności cykliczne wynikają z próby modelowania relacji, które nie należą do jednego poziomu abstrakcji.
- Trzecia postać normalna (3NF): Upewnij się, że atrybuty niekluczowe zależą wyłącznie od klucza głównego. Jeśli tabela zawiera klucz obcy wskazujący na samą siebie w celu przedstawienia hierarchii, rozważ oddzielenie logiki hierarchii w osobnej tabeli relacyjnej.
- Usuń nadmiarowość: Jeśli encja A i encja B odnoszą się do siebie wzajemnie, zastanów się, czy jeden z tych odniesień jest nadmiarowy. Czy relacja może być przedstawiona tylko w jednym kierunku?
2. Wprowadź tabelę pośrednią
Relacje wiele do wielu są częstym źródłem pętli cyklicznych. Zamiast umieszczać klucze obce bezpośrednio w głównych encjach, użyj tabeli pośredniej.
Na przykład, jeśliUczniowie i Kursy mają relację wiele do wielu, nie dodawaj course_id do tabeli Uczniowie i student_id do tabeli Kursy tabeli. Zamiast tego utwórz tabelę Zapisytabelę przechowującą oba identyfikatory. To niszczy bezpośredni link między dwiema głównymi encjami.
3. Użyj widoków do relacji logicznych
Czasem fizyczne przechowywanie danych nie musi odzwierciedlać wymogu logicznego. Jeśli aplikacja potrzebuje zobaczyć relację między A i B, ale jej bezpośredni zapis tworzy cykl, użyj widoku bazy danych.
- Model fizyczny: Przechowuj A i B bez bezpośredniego linku klucza obcego.
- Model logiczny: Utwórz widok łączący A i B na podstawie wspólnego atrybutu lub osobnej tabeli relacyjnej.
To rozdziela ograniczenia przechowywania od logiki aplikacji, umożliwiając bazie danych zapewnienie integralności tam, gdzie ma to znaczenie, bez tworzenia fizycznych pętli.
4. Zaimplementuj miękkie odniesienia
W niektórych przypadkach nie jest wymagane ścisłe zapewnienie integralności referencyjnej dla relacji. Możesz przechowywać identyfikator powiązanej encji jako zwykłą kolumnę typu całkowitego zamiast ograniczenia klucza obcego.
- Zalety: Usuwa sprawdzanie ograniczeń podczas wstawiania/usuwania, umożliwiając istnienie pętli fizycznie bez blokowania operacji.
- Wady: Baza danych już nie zapewnia relacji. Logika aplikacji musi sprawdzać, czy odwoływany identyfikator istnieje.
📊 Porównanie podejść do refaktoryzacji
| Podejście | Złożoność | Zapewnienie integralności | Najlepsze zastosowanie |
|---|---|---|---|
| Normalizacja | Wysoka | Pełne | Gdy nadmiarowość danych jest przyczyną problemu. |
| Tabela pośrednicząca | Średnia | Pełne | Relacje wiele do wielu. |
| Widoki | Niska | Częściowe (na poziomie zapytania) | Raportowanie lub obciążenia o wysokim natężeniu odczytu. |
| Miękkie odniesienia | Niska | Brak (na poziomie aplikacji) | Systemy dziedziczne lub opcjonalne relacje. |
🛡️ Zapobieganie i najlepsze praktyki
Po refaktoryzacji schematu skupienie przesuwa się na zapobieganiu przyszłym cyklom. Wzorce projektowe i procesy zarządzania mogą zmniejszyć ryzyko ponownego wprowadzenia tych problemów.
1. Zdefiniuj kierunek relacji
Ustanów zasade, że klucze obce zawsze powinny przepływać w określonym kierunku. Na przykład tabele potomne zawsze powinny odwoływać się do rodziców, nigdy w przeciwnym kierunku. Jeśli rodzic potrzebuje uzyskać dostęp do danych potomnych, użyj zapytania lub widoku zamiast klucza obcego.
2. Czujnie modeluj hierarchie
Tabele samodzielne są powszechne w przypadku wykresów organizacyjnych lub wątków komentarzy. Aby zapobiec pętlom:
- Tylko rodzic: Przechowuj tylko
parent_id. Nie przechowujchildren_idsw tym samym wierszu. - Wyliczanie ścieżki: Dla głębokich hierarchii przechowuj pełny ciąg ścieżki (np.
/1/5/9/) aby umożliwić szybkie wyszukiwanie bez rekurencyjnych połączeń.
3. Automatyczne audyty schematu
Zintegruj wykrywanie pętli w procesie CI/CD. Skrypty mogą analizować pliki definicji schematu (takie jak skrypty migracji SQL) i oznaczać wszystkie nowe definicje kluczy obcych, które tworzą pętlę przed wdrożeniem.
4. Dokumentacja
Utrzymuj aktualny diagram ERD. Gdy programista dodaje tabelę, powinien aktualizować diagram. To narzędzie wizualne pomaga wykryć potencjalne pętle przed napisaniem kodu. Narzędzia generujące automatycznie dokumentację na podstawie schematu bazy danych są bardzo zalecane dla dużych zespołów.
🔄 Obsługa systemów dziedziczonych
Refaktoryzacja bazy danych produkcyjnej nie zawsze jest możliwa z powodu kosztów przestojów lub objętości danych. W takich przypadkach konieczna jest faza po fazie.
- Zidentyfikuj kluczowe ścieżki: Najpierw znisz pętle wpływające na najczęściej wykonywane zapytania.
- Użyj logiki aplikacji: Przejdź tymczasowo obsługę relacji na warstwę aplikacji. Przechowuj ID jako zwykłe kolumny i sprawdzaj je w kodzie.
- Zaplanuj migrację: Zaprojektuj okno konserwacji, aby przekształcić odwołania na poziomie aplikacji w ograniczenia fizyczne, gdy nowa struktura będzie stabilna.
📝 Ostateczne rozważania dotyczące zdrowia schematu
Czysty diagram ERD to fundament solidnej aplikacji. Zależności okrężne to objaw projektu, który zwracał uwagę na wygodę zamiast na strukturę. Przestrzegając zasad normalizacji i stosując tabele pośrednie tam, gdzie to konieczne, możesz zapewnić spójność i zapytania danych.
Pamiętaj, że projekt bazy danych jest iteracyjny. Wraz z rozwojem wymagań biznesowych zmieniają się relacje. Regularnie przeglądarka schematu, aby upewnić się, że nadal odpowiada Twoim celom. Ciągła weryfikacja i dyscyplinowany podejście do kluczy obcych utrzymają Twoją architekturę odporną na złożoność rosnących potrzeb danych.