











Projektowanie solidnej struktury bazy danych wymaga precyzji i dalekowzroczności. Diagram związków encji (ERD) pełni rolę podstawowego projektu architektury. Bez jasnego mapowania szybko pojawiają się nadmiarowość danych i przepływy zapytań, co prowadzi do degradacji wydajności w czasie. Ten przewodnik omawia sposób wyprowadzania technik optymalizacji bezpośrednio z tych modeli wizualnych. Skupiamy się na integralności strukturalnej i dopasowaniu wydajności bez wykorzystywania specyficznych funkcji platformy ani własnościowych narzędzi. Zrozumienie podstawowych relacji pozwala tworzyć systemy, które efektywnie skalują się.
📐 Zrozumienie podstaw diagramów ER
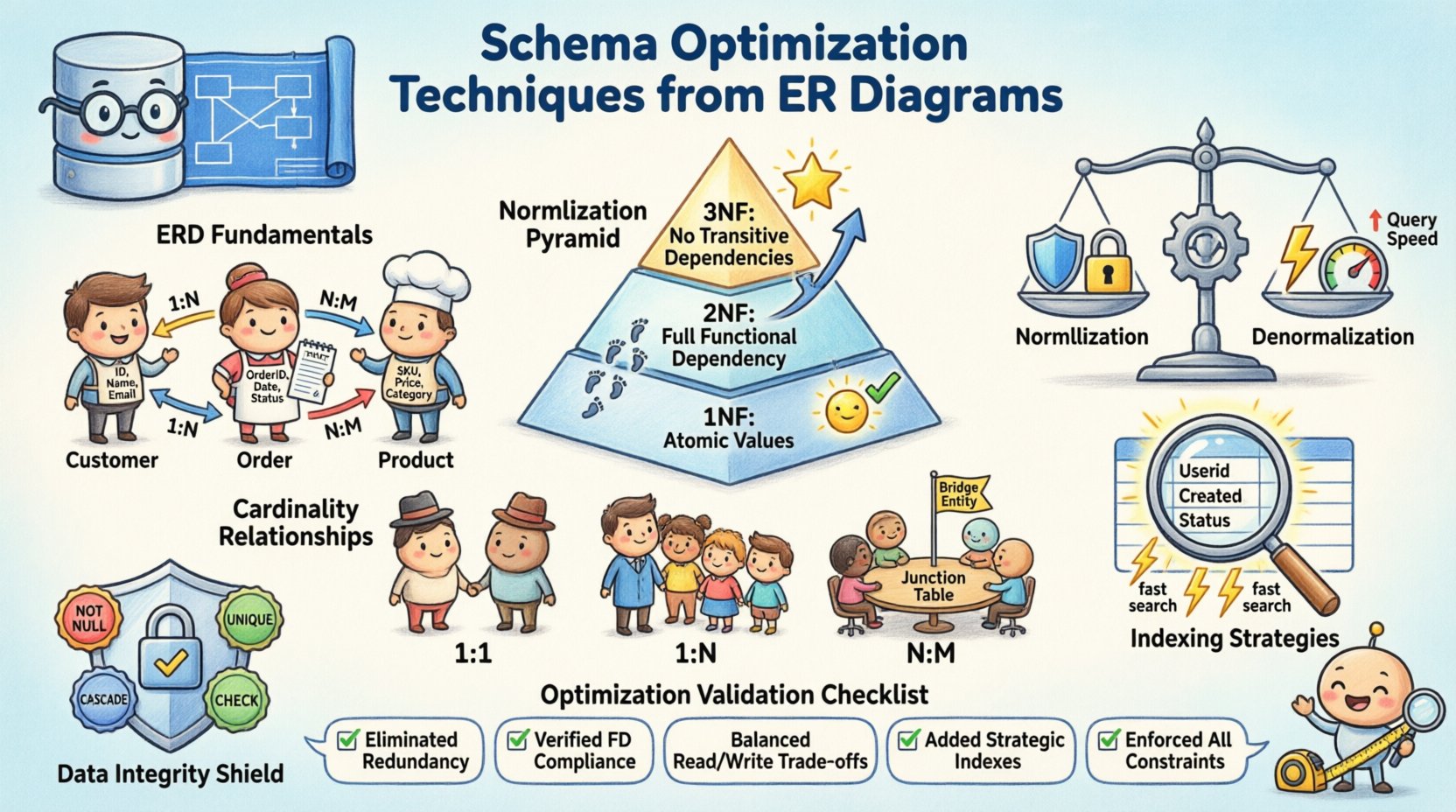
Zanim zacznie się optymalizacja, muszą być jasne podstawowe elementy. Diagram ER przekłada wymagania biznesowe na model danych logicznych. Określa, jak dane są przechowywane i dostępne. Solidna podstawa zapobiega zadłużeniu strukturalnemu na późniejszych etapach cyklu rozwoju. Rozważ następujące elementy:
- Encje: Odpowiadają obiektom lub pojęciom, takim jak klienci, zamówienia lub produkty. Każda encja staje się tabelą w schemacie fizycznym.
- Atrybuty: Określają właściwości encji, takie jak nazwa, identyfikator lub znacznik czasu. Stanowią one kolumny w tabelach.
- Związki: Pokazują, jak encje wzajemnie się oddziałują. Wyznaczają sposób używania kluczy obcych i ograniczeń.
Wizualizacja tych elementów pozwala wykrywać potencjalne problemy jeszcze przed napisaniem jednej linii kodu. Zapewnia, że przepływ logiczny odpowiada wymaganiom przechowywania fizycznego. To dopasowanie jest kluczowe do utrzymania spójności danych w złożonych aplikacjach.
🔨 Strategie normalizacji dla integralności danych
Normalizacja to proces organizowania danych w celu zmniejszenia nadmiarowości i poprawy integralności. Polega na dzieleniu dużych tabel na mniejsze, logiczne jednostki. Choć nadmierna normalizacja może spowolnić odczyty, jej całkowite pominięcie powoduje anomalie aktualizacji. Celem jest znalezienie równowagi odpowiedniej dla Twojego konkretnego obciążenia.
Pierwsza postać normalna (1NF)
Pierwsze założenie wymaga, by każda kolumna zawierała wartości atomowe. W jednym polu nie wolno umieszczać powtarzających się grup ani tablic. Zapewnia to, że każdy fragment danych jest jednoznaczny i możliwy do zapytania. Na przykład lista numerów telefonów powinna zostać podzielona na osobne wiersze lub oddzielną tabelę, a nie przechowywana jako ciąg rozdzielony przecinkami.
Druga postać normalna (2NF)
Po spełnieniu 1NF, 2NF rozwiązuje zależności częściowe. Wszystkie atrybuty niekluczowe muszą zależeć od całego klucza głównego. W przypadku kluczy złożonych zapobiega to powielaniu danych, gdy tylko część klucza decyduje o wartości atrybutu. Ten krok dopasowuje strukturę, aby każda informacja była poprawnie powiązana z jej rodzicem.
Trzecia postać normalna (3NF)
Trzecia postać normalna eliminuje zależności przechodnie. Atrybuty niekluczowe nie powinny zależeć od innych atrybutów niekluczowych. Oznacza to, że jeśli atrybut A zależy od atrybutu B, a B zależy od klucza, to A nie powinien występować w tej samej tabeli. Przeniesienie takich danych do osobnej tabeli poprawia utrzymywalność i zmniejsza marnotrawstwo pamięci.
Poniższa tabela podsumowuje postępowanie w normalizacji:
| Postać normalna | Główny cel | Ograniczenie kluczowe |
|---|---|---|
| 1NF | Wartości atomowe | Brak powtarzających się grup |
| 2NF | Pełna zależność | Usuń zależności częściowe |
| 3NF | Niepodległość | Usuń zależności przechodnie |
⚡ Denormalizacja dla wydajności
Podczas gdy normalizacja zapewnia integralność, często wymaga skomplikowanych połączeń podczas zapytań. W systemach o dużym obciążeniu odczytu nadmiarowa obsługa połączeń wielu tabel może stać się węzłem zastojowym. Denormalizacja świadomie wprowadza nadmiarowość w celu poprawy szybkości pobierania danych. Jest to kompromis między wydajnością przechowywania a wydajnością zapytań.
Zastanów się nad poniższymi scenariuszami, w których denormalizacja jest odpowiednia:
- Panel raportów: Dane agregowane mogą być wcześniej obliczane i przechowywane, aby uniknąć obliczeń w czasie rzeczywistym.
- Warstwy buforowania: Często dostępną daną można zduplikować w magazynie zoptymalizowanym pod odczyt.
- Transakcje o wysokim przepływie: Zmniejszanie głębokości połączeń minimalizuje konkurencję blokad i zużycie procesora.
Podczas wdrażania tego rozwiązania należy ustalić jasny proces aktualizacji danych nadmiarowych. Niezgodności pojawiają się, gdy źródło prawdy zmienia się bez aktualizacji kopii. Automatyczne wyzwalacze lub logika aplikacji muszą zarządzać synchronizacją w celu zachowania dokładności.
🔗 Zarządzanie licznością i relacjami
Liczność definiuje liczbową relację między jednostkami. Określa, jak są zaimplementowane klucze obce oraz jak dane są ze sobą powiązane. Zrozumienie tych wzorców jest kluczowe do zapobiegania pozostawianiu niezwiązanych rekordów i zapewniania integralności referencyjnej.
- Jeden do jednego: Rzadko występuje w ogólnych systemach, często stosowane do tabel zabezpieczeń lub rozszerzeń. Jeden wiersz w Tabeli A łączy się dokładnie z jednym wierszem w Tabeli B.
- Jeden do wielu: Najczęstsza relacja. Jeden rekord nadrzędny łączy się z wieloma rekordami podrzędnymi. Klucz obcy znajduje się w tabeli podrzędnej.
- Wiele do wielu:Wymaga tabeli pośredniej do rozwiązania relacji. Ta tabela pośrednia łączy klucze główne obu jednostek.
Niepoprawne założenia dotyczące liczności prowadzą do nieefektywnego przechowywania danych lub nieprawidłowych stanów danych. Na przykład traktowanie relacji wiele do wielu jako prostej kolumny uniemożliwi wielokrotne powiązania. Poprawne modelowanie tych połączeń zapewnia, że baza danych może stosować zasady biznesowe określone na schemacie.
📉 Strategie indeksowania oparte na analizie strukturalnej
Indeksy to mechanizm umożliwiający szybkie znalezienie danych przez silnik bazy danych. Struktura ERD bezpośrednio wskazuje, które kolumny powinny być indeksowane. Zbyt liczne indeksy zużywają przestrzeń dyskową i spowalniają operacje zapisu.
Kluczowe kwestie dotyczące indeksowania to:
- Klucze podstawowe:Zawsze indeksowane domyślnie. Definiują unikalną tożsamość każdego wiersza.
- Klucze obce:Często wymagają indeksowania w celu przyspieszenia operacji połączeń i sprawdzania ograniczeń.
- Klucze złożone:Używane, gdy zapytania filtrowane są według wielu kolumn. Kolejność kolumn w indeksie ma znaczenie dla wydajności.
- Wybierane kolumny:Indeksuj kolumny o wysokiej kardynalności. Niska selektywność (np. płeć) rzadko korzysta z indeksu.
Analizuj wzorce zapytań w stosunku do projektu schematu. Jeśli określone łączenie jest wykonywane często, upewnij się, że kolumna klucza obcego jest indeksowana. Zmniejsza to czas, jaki baza danych poświęca na przeszukiwanie całych tabel.
🛡️ Integralność danych i ograniczenia referencyjne
Ograniczenia integralności chronią dokładność i spójność danych. Są jak bariera ochronna przed nieprawidłowymi danymi lub przypadkowym usunięciem. Choć niektóre ograniczenia są realizowane przez aplikację, ograniczenia na poziomie bazy danych są bardziej wiarygodne.
Typowe typy ograniczeń to:
- NOT NULL:Zapewnia, że kolumna zawsze zawiera wartość. Zapobiega brakom w kluczowych polach danych.
- UNIQUE:Zapewnia, że żadne dwa wiersze nie mają tej samej wartości w określonej kolumnie. Użyteczne dla adresów e-mail lub nazw użytkowników.
- CASCADE:Określa, co dzieje się z rekordami potomkami, gdy rodzic jest usunięty. Opcje obejmują ograniczenie, kaskadowe usunięcie lub ustawienie na NULL.
- CHECK:Wymusza określone warunki na wartościach danych, takie jak zakresy dat lub limity liczbowe.
Zaimplementowanie tych reguł na poziomie bazy danych zapobiega konieczności sprawdzania każdego pojedynczego punktu danych przez aplikację. Skupia logikę sprawdzania poprawności danych, zmniejszając powielanie kodu i potencjalne błędy.
🔄 Iteracyjne doskonalenie i ewolucja schematu
Projektowanie schematu to nie jednorazowa czynność. Wymagania biznesowe się zmieniają, a model danych musi ewoluować. Regularne przeglądy ERD i schematu fizycznego pomagają wykryć obszary do poprawy. Monitorowanie wydajności zapytań daje wgląd w miejsca, gdzie struktura ma trudności.
W trakcie doskonalenia rozważ następujące kroki:
- Przejrzyj użycie indeksów:Usuń nieużywane indeksy, aby zmniejszyć obciążenie zapisu.
- Sprawdź partycjonowanie:Duże tabele mogą skorzystać z podziału danych na podstawie zakresów lub kluczy.
- Zaktualizuj kardynalność:W miarę zmiany logiki biznesowej relacje mogą zmieniać się z jedno-do-wielu na wiele-do-wielu.
- Kontrola wersji:Traktuj zmiany schematu jak kod. Śledź zmiany, aby umożliwić cofnięcie, jeśli będzie to potrzebne.
Ten iteracyjny podejście zapewnia, że baza danych pozostaje zgodna z potrzebami aplikacji w czasie. Zapobiega gromadzeniu długu technicznego, który spowalnia przyszłe rozwijanie.
✅ Lista kontrolna optymalizacji
Użyj tej listy do weryfikacji projektu schematu przed wdrożeniem:
- Upewnij się, że wszystkie tabele spełniają co najmniej Trzecią Formę Normalną (3NF).
- Upewnij się, że klucze obce są indeksowane tam, gdzie często występują połączenia.
- Sprawdź obecność cyklicznych zależności w relacjach.
- Upewnij się, że klucze podstawowe są zdefiniowane dla każdej tabeli.
- Przejrzyj ograniczenia, aby upewnić się, że zasady spójności danych są stosowane.
- Analizuj wzorce zapytań, aby zidentyfikować potencjalne możliwości denormalizacji.
- Zarejestruj wszystkie założenia dotyczące liczby elementów danych i ich objętości.
Podjęcie tych kroków tworzy wytrzymałą podstawę do przechowywania danych. Pozwala systemowi radzić sobie z rozwojem bez konieczności całkowitej ponownej budowy. Dobrze zoptymalizowana schemat jest różnicą między powolną aplikacją a szybką reakcją.